Last Updated: 2023-04-02 14:10:09 Sunday
-- TOC --
1, 1958年,心理学家Rosenblatt提出了由两层神经元组成的神经网络(只有输入和输出层),起名“感知器”(Perceptron),轰动一时。这是第一个可以进行学习的人工神经网络,美国军方大力资助神经网络的研究,并一度认为其比原子弹工程更重要。
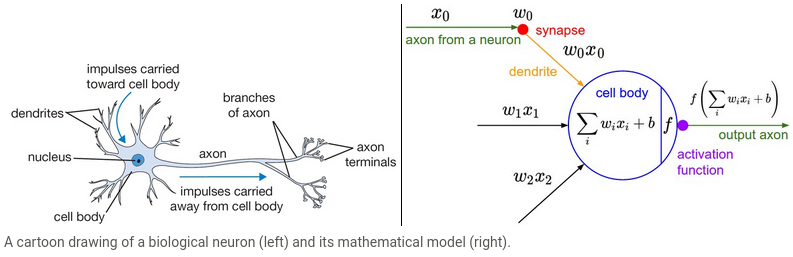
The initial idea of the perceptron dates back to the work of Warren McCulloch and Walter Pitts in 1943, who drew an analogy between biological neurons and simple logic gates with binary outputs. In more intuitive terms, neurons can be understood as the subunits of a neural network in a biological brain. Here, the signals of variable magnitudes arrive at the dendrites. Those input signals are then accumulated in the cell body of the neuron, and if the accumulated signal exceeds a certain threshold, a output signal is generated that which will be passed on by the axon.
2, Perceptron之后没几年,60年代初期,出现了Adaline(Adaptive Linear Neurons),摒弃了伐值型的神经元,采用连续的sigmoid函数,并且,梯度下降概念问世。不过Adaline也是只有输入层和输出层,没有hidden layer。
3, 1969年人工智能领域巨擘Minsky出版《Perceptron》一书,用详细的数学推导证明了(单层)感知器的弱点,即只能做线性分类任务,尤其是对于XOR(异或)这样简单的分类任务都无法求解,并且Minsky认为如果将计算层增加为两层,计算量过大,并且没有找到有效的学习算法,因此它认为研究更深层的神经网络是没有意义的(dead end),这把神经网络的研究带入了冰河期,许多学者也放弃神经网络的研究方向(看来大部分学者也是跟随型的)。
Rosenblatt further developed the artificial neuron to give it the ability to learn. Even more importantly, he worked on building the first device that actually used these principles, the Mark I Perceptron. In "The Design of an Intelligent Automaton" Rosenblatt wrote about this work: "We are now about to witness the birth of such a machine -- a machine capable of perceiving, recognizing and identifying its surroundings without any human training or control." The perceptron was built, and was able to successfully recognize simple shapes.
An MIT professor named Marvin Minsky (who was a grade behind Rosenblatt at the same high school!), along with Seymour Papert, wrote a book called Perceptrons (MIT Press), about Rosenblatt's invention. They showed that a single layer of these devices was unable to learn some simple but critical mathematical functions (such as XOR). In the same book, they also showed that using multiple layers of the devices would allow these limitations to be addressed. Unfortunately, only the first of these insights was widely recognized. As a result, the global academic community nearly entirely gave up on neural networks for the next two decades.
4, 1986年,Rumelhar和Hinton等人重新发表了反向传播(Back Propagation,BP)算法(这个算法很早就有了,只是没有被很多人注意到),减少了多层神经网络所需要的计算量,从而带动了业界使用多层神经网络研究的热潮,同时理论证明多层的神经网络可以无限逼近任何连续函数(universal approximator),带来了神经网络的又一春。(含hidden layer的神经网络,总是被认为比只有输入层和输出层结构要好,其中一个原因就是Minsky提出的perceptron不能学习XOR功能,但是如果有hidden layer后,学习XOR就可以实现了,多层神经网络被认为具有一定的feature extraction功能,可以比output layer更好的学习)
In the 1980's most models were built with a second layer of neurons, thus avoiding the problem that had been identified by Minsky and Papert (this was their "pattern of connectivity among units," to use the framework above). And indeed, neural networks were widely used during the '80s and '90s for real, practical projects. However, again a misunderstanding of the theoretical issues held back the field. In theory, adding just one extra layer of neurons was enough to allow any mathematical function to be approximated with these neural networks, but in practice such networks were often too big and too slow to be useful.
Although researchers showed 30 years ago that to get practical good performance you need to use even more layers of neurons, it is only in the last decade that this principle has been more widely appreciated and applied. Neural networks are now finally living up to their potential, thanks to the use of more layers, coupled with the capacity to do so due to improvements in computer hardware, increases in data availability, and algorithmic tweaks that allow neural networks to be trained faster and more easily. We now have what Rosenblatt promised: "a machine capable of perceiving, recognizing, and identifying its surroundings without any human training or control."
5, 尽管使用了BP算法,训练依然十分耗时,而且困扰训练优化的一个问题就是局部最优解问题,这使得神经网络的优化较为困难。同时,隐藏层的节点需要调参,这使得算法的使用也不太方便,工程和研究人员对此多有抱怨。
6, 20世纪90年代中期,由Vapnik等人发明的SVM(Support Vector Machines,支持向量机)算法诞生,很快就在若干个方面体现出了对比神经网络的优势:无需调参、高效、局部最优解。基于以上种种理由,SVM迅速打败了神经网络算法成为主流,神经网络再次陷入冰河期。
7, 在被人摒弃的十多年中,有几个学者仍然在坚持研究。这其中就有加拿大多伦多大学的Geoffery Hinton教授。2006年Hinton提出“深度信念网络”,通过pre-training和fine-tuning两个技术大幅减少了神经网络训练时间,并赋予其一个新的名字“深度学习”。
8, 2016年3月9日,世界记住了AlphaGo,神经网络和深度学习!
就是因为AlphaGo的出现,让孤陋寡闻没有见识的我,又重新走上了技术这条路,并发誓再也不离开了!
9, 2023年,chatGPT诞生!
人工神经网络的研究,在开始时,受到脑科学的一些启发,比如用数学模型模拟神经元(这种模拟也是对真实神经元的非常简单的模拟)。但现在的人工神经网络更多的是在自己独立发展。
机器学习发展分为两个部分, 浅层学习(Shallow Learning)和 深度学习(Deep Learning)。浅层学习起源上世纪人工神经网络的反向传播算法(Back-propagation)的发明,使得基于统计的机器学习算法大行其道,虽然这时候的人工神经网络算法也被称为多层感知机(Multiple Layer Perceptron),但由于多层网络训练困难,通常都是只有一层隐含层的浅层模型。
神经网络研究领域领军者Hinton在2006年提出了神经网络Deep Learning算法,使神经网络的能力大大提高,向支持向量机(SVM)发出挑战。
2006年,机器学习领域的泰斗Hinton和他的学生Salakhutdinov在顶尖学术刊物《Science》上发表了一篇文章,开启了深度学习在学术界和工业界的浪潮。
这篇文章有两个主要的讯息:
Hinton的学生Yann LeCun的LeNets深度学习网络被广泛应用在全球的ATM机和银行之中。同时,Yann LeCun和吴恩达等认为卷积神经网络CNN允许人工神经网络能够快速训练,因为其所占用的内存非常小,无须在图像上的每一个位置上都单独存储滤镜,因此非常适合构建可扩展的深度网络,卷积神经网络因此非常适合识别模型。
2015年,为纪念人工智能概念提出60周年, LeCun、Bengio和Hinton推出了深度学习的联合综述。
深度学习可以让那些拥有多个处理层的计算模型来学习具有多层次抽象的数据的表示。这些方法在许多方面都带来了显著的改善,包括最先进的语音识别、视觉对象识别、对象检测和许多其它领域,例如药物发现和基因组学等。深度学习能够发现大数据中的复杂结构。它是利用BP算法来完成这个发现过程的。BP算法能够指导机器如何从前一层获取误差而改变本层的内部参数,这些内部参数可以用于计算表示。深度卷积网络在处理图像、视频、语音和音频方面带来了突破,而递归网络在处理序列数据,比如文本和语音方面表现出了闪亮的一面。
可以认为神经网络与支持向量机都源自于感知机。
神经网络与支持向量机一直处于“竞争”关系。SVM应用核函数的展开定理,无需知道非线性映射的显式表达式,由于是在高维特征空间中建立线性学习机,所以与线性模型相比,不但几乎不增加计算的复杂性,而且在某种程度上避免了“维数灾难”。而早先的神经网络算法比较容易overfitting,大量的经验参数需要设置,训练速度比较慢,在层次比较少(小于等于3)的情况下效果并不比其它方法更优。
神经网络模型貌似能够实现更加艰难的任务,如目标识别、语音识别、自然语言处理等。但是,应该注意的是,这绝对不意味着其他机器学习方法的终结。尽管深度学习的成功案例迅速增长,但是对这些模型的训练成本是相当高的,调整外部参数也是很麻烦。同时,SVM的简单性促使其仍然最为广泛使用的机器学习方式。
本文用深度神经网络,来表示具有多hidden layer的神经网络。
最初的感知机,只有两层,input layer和output layer,因此minsky会说这样的网络连异或XOR这样的规则都学不会。但其实minsky同样也提到了,增加网络的层次,可以解决学不会XOR的问题,只是当时少有人关注到,神经网络的研究进入冰河期。
后来不管怎么样,神经网络还是在发展,科学家们证明了带有hidden layer的神经网络,实际上就是个通用函数模拟器,universal approximator,可以模拟任何函数。1986年,可加速计算梯度的BP算法重新浮出水面,让大家认识到其价值,神经网络又来了一个春天。不过,很多人的实践还是停留在只有一层hidden layer的网络结构上。只有一层hidden layer,理论上可以,但是实际上它更加消耗计算资源。假设有两个神经网络的能力一样,有多层hidden layer的网络在计算上消耗的资源,要少于只有一层hidden layer的网络,带来这个结果的原因,很可能是神经元的总数量前者要低,虽然层次更多。(如果用软件开发来类比,就是良好的分层设计,可以减少代码量,增加可维护性,更容易优化)
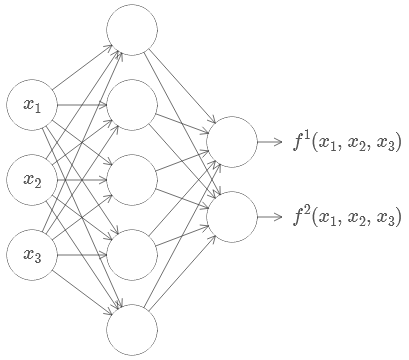
饶了这么多,我想说的第一个问题是:多层(多hidden layer)深度神经网络,这种pattern与我们很多其它方面的事情竟然保持着高度的一致!
比如我们在解决问题的时候,总是习惯性的将一个大问题,分解成一个个的小问题,甚至对小问题进行继续分解。在解决了一个个小问题后,大问题自然也就搞定了。这种大问题划分小问题的pattern,就是在分层。
比如计算机科学,就是分层的科学。硬件是最底层,然后是OS,然后是各APP。APP不与硬件直接交互,要通过OS。这是大的分层,硬件和软件内部,都还有着非常多的更细分的层次。硬件我不太懂,就说软件,一条非常经典的设计原则是,机制和策略分离,这就是分层,底层是机制,上层是策略,底层的策略还可以继续作为高层策略的机制而存在。软件设计讲究封装和解耦合(隔离),本质也是分层,相互之间仅通过API通信,看不到各自内部的实现细节。
TCP/IP网络,也是典型的分层结构:物理层,链路层,IP层,TCP/UDP层,应用层。
下面摘一段文字,说明在做硬件电路设计的时候,层次化的设计能够大幅减少门电路的数量:
So deep circuits make the process of design easier. But they're not just helpful for design. There are, in fact, mathematical proofs showing that for some functions very shallow circuits require exponentially more circuit elements to compute than do deep circuits. For instance, a famous series of papers in the early 1980s (The history is somewhat complex, so I won't give detailed references. See Johan Håstad's 2012 paper On the correlation of parity and small-depth circuits for an account of the early history and references. ) showed that computing the parity of a set of bits requires exponentially many gates, if done with a shallow circuit. On the other hand, if you use deeper circuits it's easy to compute the parity using a small circuit: you just compute the parity of pairs of bits, then use those results to compute the parity of pairs of pairs of bits, and so on, building up quickly to the overall parity. Deep circuits thus can be intrinsically much more powerful than shallow circuits.
分层的好处是显而易见的,各自解决各自的问题,相互之间保持一定的独立性,独立发展,内部结构也很清晰。能够被分层分解的,都是可以更好解决或更好发展的。所有这一切,我感觉都与多hidden layer的神经网络,神似!从输入层到输出层,中间很多hidden layer,各自干着我们现在还说不清道不明的事情。
神经网络的第二个迷人的地方是:它是由很多很多极其简单的小单位,组合而成的可以表现出一定智慧的计算结构!这种由很多简单的小单位,组合而成为功能强大的大单位的结构,感觉很上道!
比如著名的生命游戏......(还不太懂)
比如有机体的结构,有无数细胞构成,单个细胞啥都不是,组合在一起,就成了生命。
比如人类社会,每个人都是一个小单位,组合在一起就成了家庭,公司,国家......如果人类社会是一台计算机,它的输出层是什么?
词穷了,能想到很多,但已经不知道该如何表达。多层深度神经网络,就像自然界的很多其它事物,他们之间在很深很本质的层面上,有着惊人的高度的一致性。从这个角度来看现在神经网络和深度学习的成功,就是很自然的结果。神经网络如果不是最终人工智能的载体,还能是什么?
本文链接:https://cs.pynote.net/ag/ml/202207061/
-- EOF --
-- MORE --