Last Updated: 2023-04-02 14:10:09 Sunday
-- TOC --
本文尝试汇总个人遇到的各类常用的神经元激活函数(activation function)。文本公式中的 \(z\),都是 weighted sum of all inputs,神经元激活之前的值:
$$\begin{align} z & = w^{T}a + b \notag \\ & = \sum_{j}w_{j}a_{j} + b \notag \end{align}$$
\(a\)是输入,它是前一层神经元的输出(激活值),或是最外层的输入,作为这一层的输入,\(w\)是对应的weights。以上公式所有值都是vector。
神经元激活函数都是非线性的,为什么需要它们?
Activation functions are an essential component of artificial neural networks. Without them, neural networks would not be able to learn and generalize from the input data.
The primary purpose of an activation function is to
introduce non-linearity into the output of a neuron. By doing so, it enables the neural network to approximate a wider range of functions, including those that are non-linear in nature. Without this non-linearity, the neural network would be limited to only linear transformations of the input data. 如果没有激活函数的非线性转换,神经网络也就只能实现对输入数据的线性转换。Activation functions also help in
normalizing the output of a neuron. Normalization ensures that the output values fall within a specific range, typically between 0 and 1 or -1 and 1. This normalization helps to prevent the output values from becoming too large or too small, which could make training the neural network more difficult.Finally, activation functions provide a mechanism for
introducing sparsity into the neural network. Sparsity means that only a small percentage of the neurons in the network are active at any given time. This feature can help reduce the computational complexity of the network and improve its performance. 比如使用ReLU神经元激活函数。So, activation functions are necessary because they introduce non-linearity, normalize the output, and enable sparsity in the neural network.
也叫logistic函数,似乎教科书都是从sigmoid神经元激活函数开始讲起。
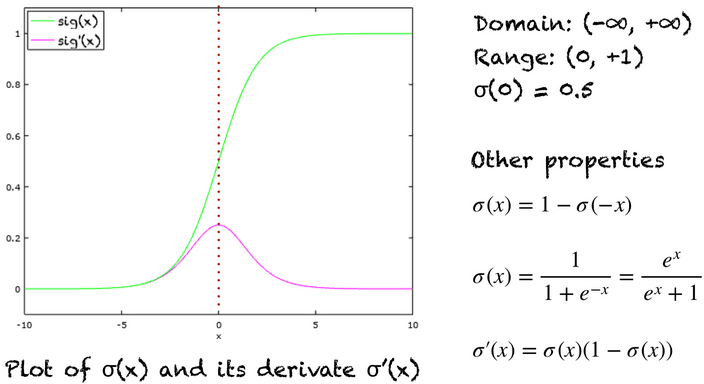
sigmoid函数公式如下:
\(sigmoid(z) = \sigma(z) = \cfrac{1}{1+e^{-z}}\)
对\(z\)进行求导,导数可以表达为:
\(\sigma'(z) = \sigma(z) \cdot (1-\sigma(z))\)
The derivative of the sigmoid function can be expressed in terms of the function itself, making it easy to compute gradients and update model parameters during training.
sigmoid函数图像:
sigmoid名称的由来
The name "sigmoid" comes from the Greek word "sigmoides", which means "shaped like the letter sigma (Σ)". The sigmoid function has an S-shape, which resembles the capital letter sigma in the Greek alphabet. This shape is characterized by a gradual increase in the output value as the input value increases from negative infinity to positive infinity. This gradual increase is particularly useful for modeling probabilities, which is why the sigmoid function is commonly used in logistic regression.
什么是逻辑回归(logistic regression)?
这个术语中的logistic,就是来自sigmoid函数的另一个名字,logistic函数。而regression表达的含义是,sigmoid可以将任意实数,转换到0到1之间(可解释为概率)。
Logistic regression is a statistical method used for
binary classificationproblems. It is a supervised learning algorithm that models the relationship between a binary dependent variable (also known as the target variable) and one or more independent variables (also known as features). The goal of logistic regression is to predict the probability of the dependent variable taking a particular value (usually 1 or 0) based on the values of the independent variables.Logistic regression works by fitting a logistic function (also called sigmoid function) to the data. The output of this function is a probability score between 0 and 1, which can be interpreted as the likelihood of the event occurring given the values of the input variables. To make a prediction, the output of the logistic function is compared to a threshold value (usually
0.5), and if the probability score exceeds this threshold, the model predicts that the event will occur (class 1); otherwise, it predicts that it will not occur (class 0).Logistic regression is widely used in fields such as healthcare, marketing, finance, and social sciences, where predicting the likelihood of an event or outcome is important. It is also popular because it is relatively easy to implement and interpret, and it can handle both linear and nonlinear relationships between the input variables and the target variable.
A single neuron can be used to implement a binary classifier.
逻辑回归使用sigmoid函数的原因
The sigmoid or logistic function is used in logistic regression for several
reasons:
- It maps any real-valued input to a probability score between 0 and 1, which is exactly what we need for binary classification problems. We can interpret the output of the logistic regression model as the probability that the input belongs to the positive class.
- The sigmoid function has a nice mathematical property that makes it convenient for optimization using gradient descent. The derivative of the sigmoid function can be expressed in terms of the function itself, making it easy to compute gradients and update model parameters during training.
- The sigmoid function is a smooth and continuous function that is differentiable at every point. This makes it possible to use gradient-based optimization algorithms to find the optimal values of the model parameters.
- The sigmoid function is
symmetric around x=0, which means that it has a balanced response to positive and negative inputs. This property is desirable for many classification problems where the classes are roughly balanced.Overall, the sigmoid function provides a simple and effective way to model the relationship between the input variables and the binary output variable in logistic regression.
sigmoid的缺点
In practice, the sigmoid non-linearity has recently fallen out of favor and it is rarely ever used. It has two major drawbacks:
1. Sigmoids saturate and kill gradients. A very undesirable property of the sigmoid neuron is that when the neuron’s activation saturates at either tail of 0 or 1, the gradient at these regions is almost zero (梯度消失). Additionally, one must pay extra caution when initializing the weights of sigmoid neurons to prevent saturation. For example, if the initial weights are too large then most neurons would become saturated and the network will barely learn. 注意saturation这个概念。
sigmoid的导数最大值才0.25,很容易导致梯度消失。
2. Sigmoid outputs are not zero-centered. This is undesirable since neurons in later layers of processing in a Neural Network would be receiving data that is not zero-centered. This has implications on the dynamics during gradient descent, because if the data coming into a neuron is always positive (e.g. \(x>0\) elementwise in \(f=w^Tx+b\)), then the gradient on the weights \(w\) will during backpropagation become either all be positive, or all negative (depending on the gradient of the whole expression f). This could introduce undesirable zig-zagging dynamics in the gradient updates for the weights. However, notice that once these gradients are added up across a batch of data the final update for the weights can have variable signs, somewhat mitigating this issue. Therefore, this is an inconvenience but it has less severe consequences compared to the saturated activation problem above.
也叫hyperbolic tangent function,公式如下:
\(tanh(z) = t(z) = \cfrac{e^z-e^{-z}}{e^z+e^{-z}}\)
tanh函数对\(z\)求导的结果为:
\(t'(z) = 1 - t(z)^2\)
tanh激活函数与sigmoid函数有着相似的曲线,也有明显不同:
1,同样存在梯度消失的问题,但比sigmoid要稍微好一些。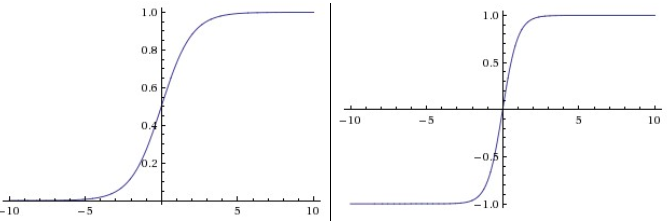
Therefore, in practice the tanh non-linearity is always preferred to the sigmoid non-linearity.
tanh就是sigmoid的rescale版本:
\(tanh(z) = 2\sigma(2z) - 1\)
用这个公式计算,可能少算几次np.exp。
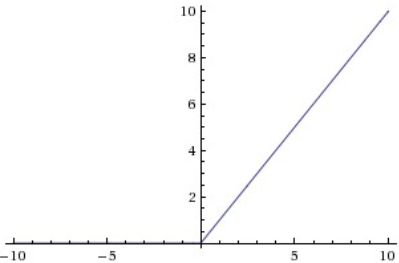
Rectified Linear Unit,最近几年很火,它的计算公式为:
$$relu(z) = \text{max}(0,z)$$
导数(此处为subderivative):
$$relu'(z) = \begin{cases} 1, & \text{if } z > 0 \\ 0, & \text{if } z \le 0 \end{cases}$$
Unfortunately, ReLU units can be fragile during training and can “die”. For example, a large gradient flowing through a ReLU neuron could cause the weights to update in such a way that the neuron will never activate on any datapoint again. If this happens, then the gradient flowing through the unit will forever be zero from that point on. That is, the ReLU units can irreversibly die during training since they can get knocked off the data manifold. For example, you may find that as much as 40% neuron of your network can be “dead” (i.e. neurons that never activate across the entire training dataset) if the learning rate is set too high. With a proper setting of the learning rate this is less frequently an issue.
有一种说法,死掉一部分ReLU没关系,正好符合了在生物神经领域发现的神经元的稀疏性!但可以肯定的是,死的太多了也不行......
貌似ReLU神经元激活函数是在2011左右出现的,著名的AlexNet就使用了它。ReLU神经元激活函数的出现,同样也是来自生物神经科学领域的启发。它给神经网络技术带来的好处是:
Learning Rate设置过大,确实是个问题。可以让ReLU彻底死掉,也可能出现overshooting现象,即cost不断变大。
我们在训练神经网络的时候,一般采用SGD算法,即小批量地更新weights和bias,每一次更新weights和bias前,都会将一组input数据的梯度进行算术平均,可能有些ReLU对某个input输出0,但是对其它的input输出就不是0,这样计算平均,梯度为非0,其对应的weights和bias依然可以得到更新。那些死掉的ReLU,是对所有input的输出都是0的顽固份子。有人说,这其实又是另外一种“梯度消失”。
Leaky ReLUs are one attempt to fix the “dying ReLU” problem. Instead of the function being zero when x < 0, a leaky ReLU will instead have a small positive slope (of 0.01, or so).
Leaky ReLU计算公式:
$$f(x)=1(x<0)(ax)+1(x>=0)(x)$$
\(a\) is a small constant。
让a成为一个参数,
PReLU,http://arxiv.org/abs/1502.01852
https://arxiv.org/abs/1302.4389
- “What neuron type should I use?” Use the ReLU non-linearity, be careful with your learning rates and possibly monitor the fraction of “dead” units in a network. If this concerns you, give Leaky ReLU or Maxout a try. Never use sigmoid. Try tanh, but expect it to work worse than ReLU/Maxout.
- It is very rare to mix and match different types of neurons in the same network, even though there is no fundamental problem with doing so.
- Notice that when we say N-layer neural network, we do not count the input layer.
- Unlike all layers in a Neural Network, the output layer neurons most commonly do not have an activation function (or you can think of them as having a linear identity activation function). This is because the last output layer is usually taken to represent the class scores (e.g. in classification), which are arbitrary real-valued numbers, or some kind of real-valued target (e.g. in regression).
- The two metrics that people commonly use to measure the size of neural networks are the number of neurons (without input layer), or more commonly the number of parameters.
- Repeated matrix multiplications interwoven with activation function. One of the primary reasons that Neural Networks are organized into layers is that this structure makes it very simple and efficient to evaluate Neural Networks using matrix vector operations.
本文链接:https://cs.pynote.net/ag/ml/ann/202302011/
-- EOF --
-- MORE --