-- TOC --
Shannon-Fano算法其实是最早的变长无损压缩编码算法,比Huffman算法早一点点,其压缩效率比Huffman稍差一点点,因此没有后者有名。
Shannon-Fano算法在以下两个重要的方面都跟Huffman算法一样:
Shannon-Fano算法与Huffman算法不同的地方,在于如何构建获得符号编码的二叉树。Huffman算法通过buttom-up(从底向上)的方法构建,而Shannon-Fano算法用top-down(从顶想下)的方法构建。
Shannon-Fano算法会将符号按出现频率从大到小的顺序排列。然后:
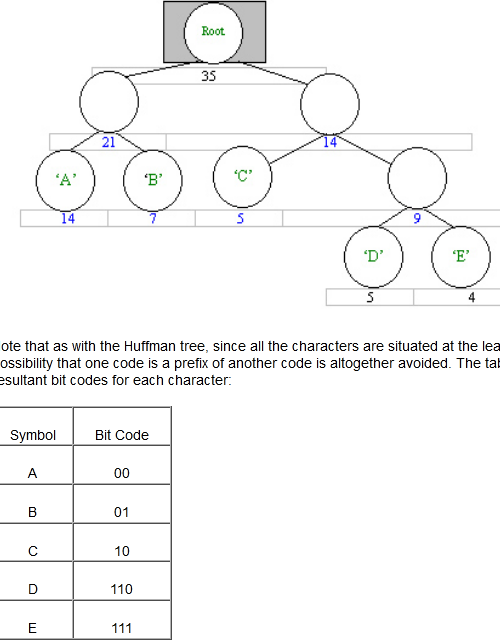
可以看出Shannon-Fano构建二叉树的方法,要比Huffman稍微复杂一点,而且得到的编码有的时候并不是最短的,Huffman算法在总体上的效率,好于Shannon-Fano算法。
上图是个例子,同学们可以自己用Huffman从底到上的方法试一,看看得到的编码有什么不同。
In general, Shannon-Fano and Huffman coding will always be similar in size. However, Huffman coding will always at least equal the efficiency of the Shannon-Fano method, and thus has become the preferred coding method of its type (Nelson, 38). 有人写论文来证明Huffman是更好的算法。
本文链接:https://cs.pynote.net/ag/202302023/
-- EOF --
-- MORE --