Last Updated: 2023-11-23 15:21:36 Thursday
-- TOC --
链表,相对来说,是一种比较简单的而且很容易理解的数据结构。本文提供两套链表的Python实现,分别对应双向链表(Doubly-Linked)和单链表(Singly-Linked)。实现特点为,它们均有一个不保存实际数据的Head节点,它的存在,让实现代码简单优雅。
有些教授使用sentinel node来表达这个head node,其实都一样...
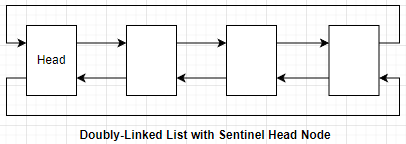
在学习数据结构和算法这门课的时候,遇到了Doubly-Linked List with Sentinel这种循环双向链表结构。我对这个结构情有独钟,因为其实现代码,可以完全无视任何特殊情况,代码简洁优雅流畅。而实现这种效果的关键,就是那个Sentinel节点(头节点),它的存在,让实现代码对特殊情况的处理与普通情况的处理,完全一样!下面是我自己的一个Python实现:
class DLinkedList():
""" No Edge Cases Implementation """
class Node():
def __init__(self, v, prior=None, next=None):
self.val = v
self.prior = prior
self.next = next
def __init__(self):
self.head = DLinkedList.Node(None) # sentinel head node
self.head.prior = self.head.next = self.head
self.size = 0
def __len__(self):
return self.size
def __iter__(self):
p = self.head.next
while p is not self.head:
yield p.val
p = p.next
def prepend(self, v):
self.head.next.prior = self.head.next = DLinkedList.Node(v,
self.head, self.head.next)
self.size += 1
def append(self, v):
self.head.prior.next = self.head.prior = DLinkedList.Node(v,
self.head.prior, self.head)
self.size += 1
def insert(self, idx, v):
assert idx >= 0 and idx <= len(self)
node = self.head.next
for _ in range(idx):
node = node.next
node.prior.next = node.prior = DLinkedList.Node(v, node.prior, node)
self.size += 1
def __getitem__(self, idx):
assert idx >= 0 and idx < len(self)
node = self.head.next
for _ in range(idx):
node = node.next
return node.val
def __setitem__(self, idx, v):
assert idx >= 0 and idx < len(self)
node = self.head.next
for _ in range(idx):
node = node.next
node.val = v
def __delitem__(self, idx):
assert idx >= 0 and idx < len(self)
node = self.head.next
for _ in range(idx):
node = node.next
node.next.prior = node.prior
node.prior.next = node.next
self.size -= 1
# test code
a = DLinkedList()
a.prepend(0)
a.append(3)
a.insert(1,1)
a.insert(2,2)
a.insert(len(a),4)
print([i for i in a]) # [0,1,2,3,4]
del a[0]
del a[3]
print([i for i in a]) # [1,2,3]
a[0] = 11
a[1] = 22
a[2] = 33
for i in range(len(a)):
print(a[i])
因为sentinel head node的存在,以上实现的所有接口,均无视各种边缘情况。
初始时,只有Head节点,它的prior和next都指向自己。Head节点一直保持不变,它的value其实是很有用的,可以利用这个空间来保存size!
引入Cursor
如果场景是在某个index附近频繁的移动,可以考虑在linked list数据结构内,引入一个cursor。用cursor记录下当前的index,通过cursor进行频繁的近距离移动,就规避了linked list做indexing的性能消耗。就像是我现在正在使用的记事本,光标就是cursor,在正常输入过程中,就是在cursor附近近距离移动。
了解Skip List
另一个对抗linked list缓慢indexing的手段,就是用更多的内存,在node节点中,存放更多的指针。上面的代码,node中只存放前后两个指针,还可以存放间隔1个node的指针,间隔3个node的指针......memory is cheap!
单链表如果配上一个sentinel head node,也一样有消除edge case code的效果。如下是一个我自己的实现:
class SLink:
class Node:
def __init__(self, v, next=None):
self.val = v
self.next = next
def __init__(self):
# sentinel head node
self.head = self.tail = SLink.Node(None)
self.size = 0
def append(self, v):
self.tail.next = self.tail = SLink.Node(v)
self.size += 1
def prepend(self, v):
self.head.next = SLink.Node(v, next=self.head.next)
self.size += 1
def __iter__(self):
p = self.head.next
while p:
yield p.val
p = p.next
def reverse_iter(self):
def __reverse(node):
if node:
yield from __reverse(node.next)
yield node.val
yield from __reverse(self.head.next)
def reverse(self):
""" no new node is created """
p = self.head.next
for i in range(self.size//2):
q = p
for j in range(self.size-i*2-1):
q = q.next
p.val, q.val = q.val, p.val
p = p.next
def reverse2(self):
""" create a whole new SLink """
s = SLink()
p = self.head.next
while p:
s.prepend(p.val)
p = p.next
self.head = s.head
self.tail = s.tail
测试代码:
s = SLink()
for i in range(10):
s.append(i)
for i in range(-1,-10,-1):
s.prepend(i)
print([i for i in s])
print([i for i in s.reverse_iter()])
s.reverse()
print([i for i in s])
print([i for i in s.reverse_iter()])
s.reverse2()
print([i for i in s])
print([i for i in s.reverse_iter()])
单链表的问题是,反过来遍历比较麻烦,因为节点没有prev指针。上面的示例代码,使用了递归的方式实现反向遍历。(这很像是递归遍历二叉树的代码风格)
单链表的反转也比较麻烦,上面的示例代码提供了两种反转的实现方式,一种是不创建新节点,直接交换节点所包含的值,另一种是通过创建新节点的方式,一边遍历一遍prepend到新的链表。
关于singly-linked单链表的反转,还有其他更好的实现方式,请参考如下两道LeetCode题:
LeetCode常常出现单链表的题,因为单链表处理起来比较麻烦,有一个常规的思路,通过遍历一次单链表,将其转换成array,此时indexing就非常简单了,只是多用点内容而已。
本文链接:https://cs.pynote.net/ag/202311021/
-- EOF --
-- MORE --