-- TOC --
原始视频数据非常庞大,如果不压缩,就难以传输和复制。视频编码(video codec)就是指视频压缩和解压的专业术语。视频压缩一般都是有损的,这样可以在不影响视觉效果的前提下,达到更好的压缩效率。无损压缩的压缩效率会低很多。本文是一篇读书笔记。
视频压缩算法的原理:移除视频数据中的时间冗余,空间冗余,以及频率冗余信息,然后通过熵编码(比如哈夫曼编码等)进一步压缩。时间冗余指在时间上相邻的frame中,存在大量没有变化的数据;空间冗余指:在同一个frame中,有很多低频区域,这些区域内的数据没有变化;频率冗余指frame中可以去掉的高频数据(比如用低通滤波器(LPF)做图像背景虚化,去掉后数据能减少,也符合视觉效果需求)。
在时间上相邻的frame,存在大量的 temporal redundancy,fps越大,这种冗余就越多。在空间上,相邻pixel值通常也强相关。
motion compensated prediction,运动补偿,motion compensation 是指将 参考帧(reference frames)的部分区块,通过 motion vector, 补偿到当前的frame中的这个动作,最后得到的结果current frame的一个prediction(predictor)。因此 current frame - prediction = residual frame。参考帧对于当前帧,可以是过去的,也可以是将来的(H.264的B,是用过去和将来的frame,合在一起取平均),目的是得到更好的prediction,so less energy is contained in the residual frame。可以想象,如果仅仅是简单的用当前帧减去前一帧,得到的residual frame一定有比较高的energy,为了减少energy,用motion compensation技术。但是这个技术不是万能的,有一些motion is very hard to compensate,比如 deformable objects,rotation, warping,complex motion such as a cloud of smoke。
理论上,以pixel为单位进行motion compensation,可以得到一个energy为全0的residual frame,但是带来的问题是motion vector数量超大,每个pixel对应一个vector,还不如不压缩呢,没有实际意义。而且,计算量也是巨大的。因此,motion compensation 都是 block-based。
Block-based motion estimation and compensation,假设一个当前帧中MxN大小的block,在参考帧中去search the best match block with the same size。search有不同的策略,best match也有不同的criterion(比如两个MxN block相减之后energy最小),tradeoff with computation cost,这个过程就是 motion estimation,输出 motion vector。
macroblock,宏块,16x16大小,这个概念在MEPG-1,MPEG-2,MPEG-4 Visual,H.261,H.263,H.264中都被使用。(H.265突破了macroblock的限制,CTU可以到64x64)
encoder内含有一个小型的decoder!在decoder端,参考帧也是decode出来的,为了保证encoder和decoder使用相同的参考帧数据进行编码和解码,encoder需要对residual进行encode --> decode后,再使用!(一般quantization都是lossy的,除非lossless,或者不做quantization,这时encoder端可以不做decode)
用来执行motion compensation的block多大合适呢?虽然macroblock是16x16固定大小,但H.264采用的adaptive block size的方式,即根据画面性质来选择最终执行motion compensation的block size,比如变化不大的区域,就可以用16x16,充满细节和复杂变化的区域,可以用4x4大小。执行motion compensation的block size越小,得到的residual的energy就越小,即效果越好,但是overhead(motion vector)也越多,因此要选择adaptive的方式。
SAE:Sum of Absolutie Error。
Sub-pixel motion estimation and compensation。有些场景,用图像interpolation算法将block的分辨率提高,然后再做estimation和compensation,效果更好!书中有个例子:用SAE值来度量residual的energy,pixel > harl-pixel > quarter pixel。
![]()
虽然sub-pixel减少了residual的energy,但也需要在使用时权衡:
补充一个好图,可以更清晰的看到half-pixel和quart-pixel的位置:
![]()
左边有一个放大区域,其中圆点是原pixel,三角形是half,+号是quart!
region-based motion compensation。不是所有的场景,都能够在block-based模式下,取得很好的match,即很小的residual energy。MPEG-4 Visual有一些这样的工具,H.264没有。
自然图像有一个特点,每个pixel都与它周围的pixel存在相关性,这种相关性随着两个pixel之间距离的增大而减小。Residual数据的这种相关性就要弱很多。因此,通过motion compensation得到residual,其实是在做decorrelation。这里有个image model的概念(经过此model的一系列步骤后,得到的数据形式更有利于做entropy coding,这一系列的步骤的目的,就是为了entropy coding?),包含几个部分:
临近block的motion vector也存在相关性,比如一个占了很多block的object在运动,这些block的mv必然相似,相似的mv在编码时还可以进一步压缩,只对变化进行编码,motion vector difference,MVD。(predictive coding,用前面的mv来预测后面的mv,然后补偿一个difference)
关于transform:
transform分两类:
DCT(Discrete Cosine Transform)
输入X是 NxN 的一个block,Y是输出,叫做 matrix of coefficients。DCT的计算公式如下:
\(Y=AXA^T\)
\(X=A^TYA\)
从这个计算公式来看,需要 \(A^T=A^{−1}\),即A是orthogonal matrix。
\(A_{ij}=C_i \cos(\frac{(2j+1)i\pi}{2N})\)
\(C_i=\sqrt\frac{1}{N}\text{ }(\text{when }i=0)\text{, }C_i=\sqrt\frac{2}{N}\text{ }(\text{when }i>0)\)
当N=4时,A如下:
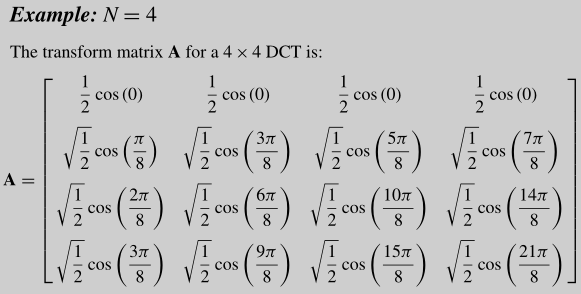
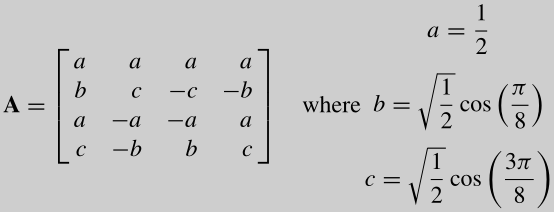
书中有一种对DCT计算后得到的coefficient的解释:These coefficients can be considered as 'weights' of a set of standard basis patterns which are composed of horizontal and vertical cosine functions. Any image block may be reconstructed by combining all NxN basis patterns, with each basis multiplied by the appropriate weighting factor (coefficient). 下图是4x4 DCT的basis patterns:

DCT的作用要通过重构图像来观察,如果我们只使用coefficient中 most significant 的那一小部分值(从大到小排序,大的就是significant),可以重构出于original图像近似的效果,使用的coefficient越多,还原出来的效果越好(coefficient越大,越重要,这跟SVD压缩图片的原理类似)。
Coefficient Distribution
The significant coefficients of a block of image or residual samples are typically the 'low frequency' positions around the DC(0,0) coefficient. The nonzero DCT coefficients are clustered around the top-left (DC) coefficient and the distribution is roughly symmetrical in the horizontal and vertical directions. 下图是个例子:
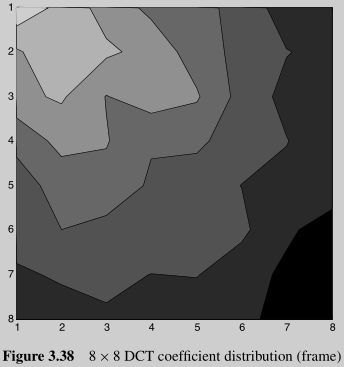
概念:DC系数,直流分量,即top left位置的那一个值;AC系数,交流分量,除了top left外的其它值。(还是不太懂)
量化(quantization)的作用,就将 transformed data 进行取值范围(具体不同值的数量)的缩小,这个过程有损,不可逆。不同值数据的数量变小了,就可以更好的进行entropy coding。量化的基本原理如下:
\(FQ=\text{round}\left(\frac{X}{QP}\right)\)
\(Y=FQ \cdot QP\)
QP是量化的 step size,这个值如果很大,可以看出量化后不同值的数量就会很小,entropy coding就会有很好的的压缩效果,但是decode之后的画面质量也更差。
量化是DCT之后的步骤,其作用是将 insignificant coefficients 映射为 0,保留那些 significant coefficients,这种保留也有精度损失,中间经过了一个round操作。这个操作得到的结果,通常是一个 sparse coefficient matrix mainly contained zeros,大量的0,少量的coefficient!
Vector Quantization:这是另一种量化方法。基本思路是采用一个codebook,里面存放codeword,每一个codeword对应一个预先定义好的图像,并且编解码双方预先已经存放了这个codebook。这就像谍战片里通信双方使用的相同的密码本。首先将图像分块,然后去在codebook寻找与每一块图像最接近的codeword,这些codeword组成一个vector。解码时反过来,用vector中的codeword去在codebook中找出一块块小图像,重新拼接成完整的图像。
这个方法还可用于 motion compensated data and/or transformed data。此方法的关键在于搜索codebook的效率。
不同编码块的QP参数可能会不一样(比如改变压缩比以匹配通道的bitrate),通常这些不同的QP参数差异都很小,因此在对这些变化编码时,对新的数值进行编码不是个好方便,对变化进行编码(比如-1,+2...),可以有更好的压缩率。比如使用Golomb压缩编码。
Scan Order (Reorder)
量化后的数据,一般有大量的0,scan的作用在于,更有效的去表示量化后的数据,将2D数据转成1D,给entropy coding提供input。一个典型的reordering path就是zigzag。
Run Level Encoding
2D run level encoding:
level: the magnitude of the nozero coefficient.
input: 16,0,0,-3,5,6,0,0,0,0,-7.......
高频DCT系数(啥意思?)常常在量化后就成了0,reorder之后的结果,也常常是最后一长串的0,再没有nonzero。3D run level encoding是在2D的基础上,增价格last indicator,用来表示后面全0的情况:
Entropy Coding
Variable Length Coding,VLC,变长编码,典型如Huffman coding。它有几个弊端:
因此有了 pre-calculated VLC ,通过在很 general 的 video material 上计算得到一组codeword set,给编解码双方直接使用。但编解码双方必须要事前存好这份codeword set。也可以通过使用exp-golobm编码codeword set。
CAVLC,Context-Adaptive VLC
Arithmetic Coding,压缩效率更接近理论最优值,代替VLC。这个算法对我来说很新颖,在得到symbol的概率分布后,对0-1这个区间不断的sub-range,在最小的range中任意取一个float number,最后用接近理论的最优bit数,对此float number进行编码。
抄个例子,我们准备对(0,-1,0,2)进行编码,首先得到这一组数字的概率分布:

编码的过程,就是不断做sub range和比较的过程:
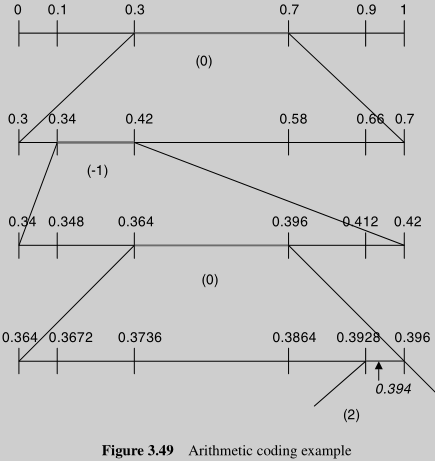
在最后的range中,任意选择0.394这个float number,用9个bit来表示,来作为对(0,-1,0,2)在给定概率分布下的编码。
解码的过程,也是一个不断寻找range,并匹配symbol的过程。
*0.394在0.3 -- 0.7之间,因此第1个symbol是0 * 重新分割 0.3 -- 0.7,发现0.394在0.34 -- 0.42之间,第2个symbol是-1 * 继续分割 0.34 -- 0.42,发现0.394在0.364 -- 0.396之间,第3个symbol是0 * 分割0.364 -- 0.396,发现0.394在0.3928 -- 0.396之间,第4个symbol是2
CABAC,Context-Based Arithmetic Coding
Hybrid DPCM/DCT Video Codec
Motion estimation and compensation,是前端,有时被称为DPCM。然后Transform和Entropy。这个model常常被称为Hybrid DPCM/DCT Video Codec Model。几乎所有的codec标准都是这个model,只是细节和实现上有很多不一样。
DCT在做什么?
In an image, most of the energy will be concentrated in the lower frequencies, so if we transform an image into its frequency components and throw away the higher frequency coefficients, we can reduce the amount of data needed to describe the image without sacrificing too much image quality.
图片数据的性质是,大量低频+少量高频,高频组成了边缘,低频填充了内容。
量化实际上就是对部分高频信号清零。Qstep用来控制选择的高频信号的范围。
There are two places in video codecs where these filters are typically used:
Motion estimation/compensation
Video codecs compress much better than still image codecs because they also remove the redundancy between frames. They do this using motion estimation and motion compensation. The encoder splits up the image into rectangular blocks of image data (typically 16x16) and then tries to find the block in a previously coded frame that is as similar as possible to the block that's currently being coded. The encoder then only transmits the difference, and a pointer to where it found this good match. This is the main reason why video codecs get about 1:100 compression, where image codecs get 1:10 compression. Now, you can imagine that sometimes camera or object in the scene didn't move by a full pixel, but actually by half or a quarter pixel. There's then a better match found if the image is scaled/interpolated, and these filters are used to do that. The exact way they do this filtering often differs per codec.
Deblocking
Another reason for using such a filter is to remove artifacts from the transform that's being used. Just like in still-image coding, there's a transform that transforms the image data into a different space that "compacts the energy". For instance, after this transform, those image sections that have a uniform color, like a blue sky, will result into data that has just a single number for the color, and then all zeros for the rest of the data. Comparing this to the original data, which stores blue for all of the pixels, a lot of redundancy has been removed. After the transform (Google for DCT, KLT, integer transform), the zeros are typically thrown away, and the other not so relevant data that's left is coded with fewer bits than in the original. During image decoding, since data has been thrown away, this often results in edges between the 8x8 or 16x16 of neighboring blocks. There's a separate smoothing filter that then smoothens these edges again.
本文链接:https://cs.pynote.net/ag/image/202211051/
-- EOF --
-- MORE --