
Last Updated: 2023-12-20 05:32:29 Wednesday
-- TOC --
文本尝试总结自己使用git命令的一些经验和积累。
几乎每一个Linux命令,都博大精深,充满了各种神秘的参数,git相关命令也不例外!世界就这样,我们只能适应...
Linus在1991年创建了开源的Linux,从此,Linux系统不断发展,已经成为最大的服务器系统软件了。那Linux的代码是如何管理的呢?事实是,在2002年以前,世界各地的志愿者把源代码文件通过diff的方式发给Linus,然后由Linus本人通过手工方式合并代码!
你也许会想,为什么Linus不把Linux代码放到版本控制系统里呢?不是有CVS、SVN这些免费的版本控制系统吗?因为Linus坚定地反对CVS和SVN,这些集中式的版本控制系统不但速度慢,而且必须联网才能使用。有一些商用的版本控制系统,虽然比CVS、SVN好用,但那是付费的,和Linux的开源精神不符。
不过,到了2002年,Linux系统已经发展了十年了,代码库之大让Linus很难继续通过手工方式管理了,社区的弟兄们也对这种方式表达了强烈不满,于是Linus选择了一个商业的版本控制系统BitKeeper,BitKeeper的东家BitMover公司授权Linux社区免费使用这个版本控制系统。
但安定团结的大好局面在2005年被打破了,原因是Linux社区牛人聚集,不免沾染了一些梁山好汉的江湖习气。开发Samba的Andrew试图破解BitKeeper的协议(这么干的其实也不只他一个),被BitMover公司发现了,于是BitMover公司怒了,要收回Linux社区的免费使用权。Linus可以向BitMover公司道个歉,保证以后严格管教弟兄们,嗯,这是不可能的。实际情况是这样的:
Linus花了两周时间自己用C写了一个分布式版本控制系统,这就是Git!一个月之内,Linux系统的源码已经由Git管理了!牛是怎么定义的呢?大家可以体会一下。
Git迅速成为最流行的分布式版本控制系统,尤其是2008年,GitHub网站上线了,它为开源项目免费提供Git存储,无数开源项目开始迁移至GitHub,包括jQuery,PHP,Ruby等等。
历史就是这么偶然,如果不是当年BitMover公司威胁Linux社区,可能现在我们就没有免费而超级好用的Git了。
跟几乎所有的版本管理控制系统不同,Git的数据存储,不是基于单个文件,而是基于snapshot,被称为snapshot stream。每一次commit,都会生成一个新的所有项目文件的snapshot。
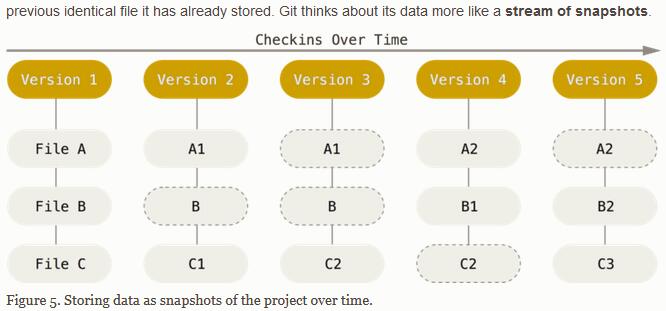
对于snapshot,Git使用SHA-1来确保数据的完整和一致。我们在使用Git的过程中,随处可见SHA-1的checksum值,这个值同时也是不同commit的索引。
所有git操作几乎都可在本地完成,不需要联网。由于Git同时也是一个分布式的版本管理系统,等到你的本地工作做完后,也有网络连接时,将积累的commit,push到云端的repo中去。我们最常用云端repo就是Github。
Git的分布式加上snapshot机制,再结合branch机制,使我们几乎可以任意拉分支来验证测试各种想法和代码,而不用担心会影响到已经commit的版本。
使用git前,首先config,我一般只做global的配置:
$ git config --global user.name XXXX
$ git config --global user.email XXX@hotmail.com
$ git config --global core.editor vim
$ git config --global credential.helper cache # 15 mininutes
上面最后一条命令是配置密码缓存,默认缓存时间为15分钟!
现在Github不允许使用账户的密码直接做git push,要使用一个人类无法记忆的token,因此,我的方法是延长缓存的时间:
$ git config --global credential.helper 'cache --timeout=3600' # 3600 seconds, 1 hour
$ git config --global credential.helper 'cache --timeout=14400' # 4 hour
$ git config --global credential.helper store # forever
--global配置用户的全局配置,--local按项目(文件夹)配置。
查看配置
$ git config --global --list
$ git config --global -l
$ git config --local -l # project local config
全局配置文件为:~/.gitconfig,项目配置文件为:~/path/to/project/.git/config
删除配置
$ git config --global --unset <item>
git global 的配置文件为: ~/.gitconfig,打开这个文件,你就会发现,直接编辑也是可以配置的!也可以用下面这个骚操作打开编辑:
$ git config --global --edit
自动pull rebase
$ git config --global pull.rebase true
配置git alias
$ git config --global alias.st status # st == status
$ git config --global alias.co checkout # co == checkout
也可以直接修改 ~/.gitconfig 文件:
[user]
name = xxx
email = xxx@gmail.com
[core]
editor = vim
[alias]
co = checkout
br = branch
ci = commit
st = status
AutoCRLF
# 提交时转换为LF,检出时转换为CRLF
$ git config --global core.autocrlf true
# 提交时转换为LF,检出时不转换
$ git config --global core.autocrlf input
# 提交检出均不转换
$ git config --global core.autocrlf false
SafeCRLF
# 拒绝提交包含混合换行符的文件
$ git config --global core.safecrlf true
# 允许提交包含混合换行符的文件
$ git config --global core.safecrlf false
# 提交包含混合换行符的文件时给出警告
$ git config --global core.safecrlf warn
走http可以不用传证书,本地也无需保存证书!
给git设置代理
$ git config --global http.proxy socks5://proxy_ip:port
修改http post buffer
$ git config --global http.postBuffer 524288000 # 500MiB
设置低速超时忍耐时间
$ git config --global http.lowSpeedLimit 0
$ git config --global http.lowSpeedTime 99999 # second
以上配置的含义,可以忍受99999秒速度为0而不timeout!
git clone 命令可以将远端的项目库克隆到你指定的任意位置,并且使用你指定的任意名称(文件夹)。此命令会默认将repo中所有branch都download下来,并在本地checkout master。
$ git clone https://github.com/xinlin-z/pingscan
# 在当前目录下clone,文件夹名称就是pingscan
$ git clone https://github.com/xinlin-z/pingscan ps
# 在当前目录下clone,文件夹名称是ps
$ git clone https://github.com/xinlin-z/pingscan ~/test/ps
# 在~/test/目录下clone,文件夹名称是ps
$ git clone https://github.com/xinlin-z/pingscan ~/test/code
# 在~/test/目录下clone,文件夹名称是code
git clone 可以带一个 -o 参数,用来修改默认的origin,建议一般别用。
自动checkout某个branch
git clone会默认checkout master,我们也可以指定一个branch:
$ git clone --branch <branch_name> <remote_repo_url>
$ git clone -b <branch_name> <remote_repo_url>
克隆单个分支
有的项目repo非常庞大,直接clone下来也太慢,硬盘空间也不一定够。或者我们知道某个功能的开发,只需要一个特定的分支,因为这个分支最后会整体被merge到master,此时我们不需要master,只需要那个特定的branch。
$ git clone --branch <branch_name> --single-branch <remote_repo_url>
$ git clone -b <branch_name> --single-branch <remote_repo_url>
在本地项目上工作了一阵了,产生了一些文件和代码,现在需要把项目用git来管理,直接在项目顶层文件夹内执行 git init。此时,项目所有文件都属于untracked,你需要git add和git commit,完成init commit。
$ git init [.]
$ git init <directory_name>
git init后,项目目录中就会多一个.git隐藏文件夹,所有git工具用到的信息都在里面。如果直接删除这个.git文件夹,相当于删除了这个git本地repo。
每天开始编码之前,用 git status 查看一下项目状态,是个好习惯!
$ git status
$ git status --short
$ git status -s

untracked 文件,如果没有作用,可以直接rm删除!
在本地提交变更!
$ git commit -m <commit_log> # commit all staged file
$ git commit -am <commit_log> # commit all modified file, they must be tracked!
我一般 -am 使用的比较多!-a 参数可以跳过staged这个状态,效率更高,但你必须知道自己在做什么...
commit log如果没有写对,是可以补救的,使用下这个命令:
$ git commit --amend
测试发现,如果只是对某个文件增加可执行权限,也算做对文件的修改,可以commit。删除后重新clone,可执行权限还在。修改权限最好使用
git update-index --chmod=+x <file>命令,特别是在windows下。This command takes your staging area and uses it for the commit. If you’ve made no changes since your last commit (for instance, you run this command immediately after your previous commit), then your snapshot will look exactly the same, and all you’ll change is your commit message.
如果没有git add,使用git commit --amend就是只是修改comments
$ git commit -m 'initial commit'
$ git add forgotten_file
$ git commit --amend
It’s important to understand that when you’re amending your last commit, you’re not so much fixing it as replacing it entirely with a new, improved commit that pushes the old commit out of the way and puts the new commit in its place. Effectively, it’s as if the previous commit never happened, and it won’t show up in your repository history.
git commit --amend并不是完全地将上一个commit替换到,只是让它看起来没有发生过,不会出现在你的项目history中。
The obvious value to amending commits is to make minor improvements to your last commit, without cluttering your repository history with commit messages of the form, “Oops, forgot to add a file” or “Darn, fixing a typo in last commit”.
当你使用git reflog命令的时候,就什么都能看到。
$ git show # show last commit
$ git show <commit_id>
一般使用git的流程,对于修改过的文件,先做git add,使这些文件处于staged状态,然后再git commit。
如果所有修改过的文件都需要commit,此时可以跳过staged状态,直接使用 git commit -am;如果只需要对部分修改过的文件commit,此时就要先用git add,将所有修改过的文件纳入staged状态,然后执行git commit -m。这样就可以实现对已修改过的文件,有选择的commit!
$ git rm <filename>
删除文件,直接进入staged状态,如果继续commit,此文件在新的commit中消失。
$ git rm --cached <filename>
与上一条命令唯一不同之处在于,这个被删除的文件,将回到untracked状态,只删除--cached,这样做更安全高效。这也是让某个文件从tracked回到untracked状态的方法。
如果直接对文件做mv,git的状态会变成,原来的文件是deleted and unstaged,新的文件处于untracked状态。
如果想一步到位做名称变更,使用:
$ git mv
然后git commit就好了。
checkout主要用来切换branch分支:
$ git checkout <branch_name>
其实checkout可以用来找出任何历史信息:
$ git checkout <tag_name>
$ git checkout <commit_id>
可以单独checkout某一个snapshot的某一个文件出来:
$ git checkout <snapshot> <filename>
单独checkout一个文件,此时此文件会处于staged状态!用这种方法,可以实现merge单个文件!
checkout一个remote分支,相当于为此remote分支新建一个本地分支,名称相同:
$ git checkout V3.0 # origin/V3.0
checkout -b,见下:
这是git非常赞的功能,拉个branch出来测试代码,用完就弃,什么都不影响。
创建新的本地branch
$ git checkout -b <branch_name>
在当前位置,创建一个新的branch出来,并checkout,-b就是branch的第一个字母。
只创建branch,不要checkout
$ git branch <branch_name>
从任意位置拉出创建branch
$ git branch <branch_name> <commit_id>
$ # check out to that position, then branch
$ git checkout <commit_id> or tag or ...
$ git checkout -b <new_branch_name>
删除本地branch
$ git branch -d <branch_name>
$ git branch -D <branch_name> # force
使用 -d 安全性较高,如果有变更没有merge,git会提示,如果知道自己在做什么可以使用 -D。只有此branch不处于checked out状态,才可以成功删除,否则会提示Error。
给本地branch重新命名
$ git branch -m <old_name> <new_name>
$ git branch -M <old_name> <new_name> # force
这个操作只在本地有效
设置本地branch与服务器branch的tracking
$ git branch --set-upstream-to=origin/<branch_name> <local_branch_name>
这个tracking在git pull/push的时候都有用,使得服务器上的branch嫩巩固跟本地branch对应起来。上面这个命令中,origin是Github的默认repo名称,需要根据实际情况修改,不是所有远端repo都叫origin。
显示所有的branch
$ git branch -a # all
$ git branch # only show local branch
$ git branch -r # only remote branch
git中的tag概念,就是一般我们确定版本时的动作,在某一个commit上打一个tag,就表示这个地方是某一个版本。
需要注意的是,git中只有tag,没有release,release是Github的概念。release是在tag上再包了一层而已,代码作者可以在release中绑定安装程序等更多的资料。我们向github push tag后,在github项目中,就能看到多了一个release。tag就是简化的release。
新建tag
$ git tag tagName
这个操作会在当前的commit上打上tag标签。
新建带注释的tag
普通tag没有注释,查看此tag的详细信息,显示的只是tag对应的commit message。
$ git tag -a tagName -m 'tag specific info'
给过往的commit打tag
$ git tag tagName commit-id
比如:git tag v1.1.1 03f9885
给过往的commit打上带注释的tag
$ git tag -a tagName commit-id -m 'tag annotation'
删除本地tag
$ git tag -d tagName
推送全部tag到远端服务器
这里有个重要的概念,git在push代码的时候,不会自动push tag,tag是附加在commit上的信息,需要单独push。
$ git push origin --tags
这个命令会将本地所有tag push到远端服务器,如果远端服务器已存在的tag与此次推送的tag有矛盾,有矛盾的会失败,git有提示。
推送某一个tag到远端仓库
$ git push origin tagName
删除远端服务器的某个tag
$ git push origin :refs/tags/tagName
貌似没有一键删除远端所有tag的命令,本地也没有。
列出所有tag
$ git tag
就这样,就可以列出项目的所有tag。不过如果tag很多,或者你想找某一类tag,需要用到 -l 参数,增加一个通配符。
$ git tag -l "V1.24.*"
这条命令就是列出所有V1.24.开头的tag。
列出tag并显示注释(annotation)
这需要用到 git tag 的 -n 参数,此参数后面可以跟一个数字,表示显示几行annotation,默认情况下,只显示第一行annotation。
$ git tag -n
查看tag的详细信息
$ git show tagName
checkout某个tag
$ git checkout tagName
跟分支一样,可以直接切换到某个tag去。但这个时候不位于任何分支,处于游离状态。
基于tag创建分支(branch)
可以考虑基于这个tag创建一个分支,如果你已经checkout到此tag,用如下命名创建分支:
$ git checkout tagName
$ git checkout -b branchName
如果你当前还没有checkout到tag,也可以直接以那个tag为基础创建分支:
$ git checkout -b branchName tagName
就总结这么多吧,一时半会儿应该够用了。
其实tag就像commit一样,以上有些命令,如果把tag换成commit的SHA-1值,也可以的。
拉取远端tag
$ git pull --tag
$ git fetch --tag
git pull 和 push 一样,对tag的处理和对代码的处理是分开的。
git的魅力,不仅仅在于本地使用,更在于远端代码仓库。git remote add就是给自己的本地代码库,增加远端仓库,保存代码!当你在Github上创建一个空白的repo,你会看到一些git命令提示:
echo "# test" >> README.md
git init
git add README.md
git commit -m "first commit"
git branch -M main
git remote add origin https://github.com/xinlin-z/test.git
git push -u origin main
origin就是指远端的Github,后面跟上地址。我们一般都使用origin这个名词来对应Github,你也可以使用别的名字,来对应这个远端的仓库!
$ git remote show [name] # show remotes
$ git remote -v # show remote repos address
$ git remote rename <old> <new>
$ git remote remove
删除远端已删除,但在本地还存在的分支
所谓本地还存在,而远端已删除,即通过git branch -a命令,还能看到的那些origin/*分支,但这些分支在origin上其实已经不存在了。
用 git remote show origin 可以看到origin上的所有已经删除但本地还有的branch,它们都处于 stale 状态。想清楚肯定不再需要这些branch之后,可以用这个命令删除:
$ git remote prune origin
首先建立远端和本地的联系
$ git push -u origin <local_branch_name> # -u is --set-upstream
$ git push origin <branch_name>
$ git push # push all branches
git push origin <local_branch_name>,直接使用这条命令,将本地branch push到origin,如果origin没有这个name的branch,就建立一个,local和remote的set upstream关系也在这个过程中自动建立。这个操作最简单!
删除远程服务器上的branch
$ git push origin :<branch_name> # a space between
$ git push origin --delete <branch_name>
推送全部tag到远端服务器
$ git push origin --tags
推送某一个tag到远端仓库
$ git push origin tagName
删除远端服务器的某个tag
$ git push origin :refs/tags/tagName
git pull 命令其实是 git fetch 和 git merge 的结合,
$ git fetch origin
$ git merge origin/master
如果本地有未push的commit,直接git pull可能会带来log分叉的问题,此时加上--rebase是个很好的选择,此时在merge之前,先rebase本地的commit。
git pull --rebase ,相当于执行:
git fetch origin
git rebase origin/master
git merge origin/master
配置rebase为pull时候默认执行的动作:
git config --global pull.rebase true
本地commit后,先pull --rebase,然后push!
pull单个分支:
$ git pull origin branch_name
将某个branch的代码与当前branch合并!
$ git branch
master
$ git merge dev # merge dev into master
在merge进master前,建议先做 git rebase master,这样这种情况不会产生新的commit,merge过程很平滑,这叫Fast-Forword。
有时merge会失败,git会提示conflicts,需要手动修改,此时可以git merge --abort来放弃此次合并,放弃后git fetch的效果还在。
merge后,删除的文件会消失,但空文件夹会保留下来!这可能会在某些时候造成问题...
我在一开始使用git的时候,感觉似乎完全用不到git rebase命令,也不太理解。现在发现rebase这个命令太重要,必须要学会使用。
这里的base指的是commit history!rebase,就是重新整理这个commit history。说清楚git rebase命令,还是从应用场景开始吧。
合并代码
团队中每个人都在自己的branch上开发测试,都在master branch上执行git merge,极大可能,你拉出branch的位置已经不再是master的HEAD。现在你的代码准备好了,要merge到master,直接在master上git merge your_branch是肯定不行的:你从master来处分支的位置已经不是head,直接merge会导致master分支的log分叉,而且所有commit会按时间先后顺序排列。
这种场景下,在merge之前,你需要做rebase:
$ git checkout master
$ git pull # pull other people's commit
$ git checkout your_branch
$ git rebase master
$ git checkout master
$ git merge your_branch
$ git push
上面这一串命令,最关键的就是rebase,,它的作用是,在master的最新的HEAD上,将your_branch的commit,重新commit一次,这个过程如果有冲突,需要手动解决。
在master分支上修改代码
一般不会这么干,这么干了其实也没有多大问题。
$ git pull --rebase
$ git push
换base
从master拉出branch1,从branch1拉出branch2,branch1现在想独立发展,branch2不想,在branch2上执行 git rebase master,让master分支成为branch2的基础,这相当于可以理解为branch2直接从master分支拉出。
整理commit历史
git仓库是用来存放代码的,当然也可以用来存放每一次的commit。我觉得commit有两种,一种是非常认真准备好的,是一个完整的feature,有配套的认真编写的message,这种commit最后要merge进master分支。另一种commit就是每天随时产生的,仅仅用来保存每天的工作进展。后一种commit在时机成熟的时候,要通过rebase来整理,形成一个前一种commit。
$ git rebase -i <commit_id> # from commit id to HEAD, exclude commit_id
$ git rebase -i <start_id> <end_id> # exclude have start_id
$ git rebase -i <start_id>^ <end_id> # include start_id
用这个功能里面的drop,可以删除中间某个commit!
commit历史重排序
使用 git rebase 命令,可以实现对 commit 历史的修改,包括重排序!
如何做呢?
git rebase -i <start_commit_id>
此时会弹出一个编辑界面,显示从start_commit_id开始(但不包括它)的所有commit,
手动调整pick commit_id的排列顺序,保存退出。
这样就完成了commit重排序,因为 git rebase 命令中的pick子命令,表示选择某个commit,调整pick的顺序,就是调整对应commit的顺序。
git rebase -i命令的这个界面,除了重排序commit,还可以合并,删除commit等操作,相当灵活。
在某branch中找出自己的commit
$ git log <branch_name> [--oneline] --author=<your_git_name>
$ git log [branch_name] # default is current branch
$ git log --oneline [-N] # show N or all onelines
$ git log -p [-N] # show patch
$ git log --stat [--oneline] [-N]
$ git log --shortstat [--oneline] [-N]
$ git log --name-only
$ git log --graph
$ git log --oneline --since="yesterday"
$ git log --oneline --since="yesterday" --author="Agil"
$ git log --oneline --since="2022-04-22" --until="2022-04-24"
$ git log --oneline --since="2022-04-22" --until="2022-04-24" --author="Agil"
git cherry-pick是一个浪漫的名称,把branch想象成树枝,上面的每个commit都是一个cherry,cherry-pick就是摘取一个commit的意思。
使用场景:当某一个分支,仅仅只需要另外一个分支里的某些commit的时候。支持不同代码库之间的pick操作。如果一个分支,需要另一个分支的全部commit,使用git merge,直接合并即可。
$ git cherry-pick <commit_id>
将指定的commit应用到当前分支,此时,当前分支会自动产生一个新的commit,id肯定不同,但是comments相同!
$ git cherry-pick -e
e表示edit,可以在cherry-pick的时候修改comments。
$ git cherry-pick -n
no-commit,将cherry-pick过来的代码,放在当前分支的staged区域,不自动commit。这个操作在向production分支pick的时候,会很有用,可以人工check。
$ git cherry-pick -x
在提交信息的末尾追加一行(cherry picked from commit ...),方便以后查到这个提交是如何产生的。
此命令还可以同时转移多个提交。
$ git cherry-pick <commitA> <commitB>
将两个commit同时转移到当前分支,这会在当前分支自动生产两个新的commit。
$ git cherry-pick <commitA>..<commitB>
上面的命令可以转移从 A 到 B 的所有提交(不包含A)。它们必须按照正确的顺序放置:提交 A 必须早于提交 B,否则命令将失败,但不会报错。
$ git cherry-pick <commitA>^..<commitB>
同上,唯一的区别是包含A。
当cherry-pick过程中发生代码冲突时,解决的方式跟其它git命令造成代码冲突的解决方法基本一样:
git cherry-pick --continue
git cherry-pick --abort
git cherry-pick --quit
abort和quit的区别是:abort放弃,回到cherry-pick前的状态;而quit不会回到操作前的样子。
这个git命令可以list所有tracking file:
$ git ls-tree -r --full-tree --abbrev HEAD | wc -l
382
所有的文件都能显示出来,就能够配合其它命令干更多事情了,比如将所有文件的mtime恢复为最后一个commit的时间。
查看某个tracking file在git库中的权限:
$ git ls-tree HEAD clean_index.sh
100644 blob a36f3e7cee5fadca87a85029fbba7e2c9eddfaf3 clean_index.sh
git reset命令可以修改HEAD指针,让你穿越时空,回到以前的某个commit后的状态。
$ git reset --hard HEAD^
$ git reset --hard <commit_id> # since commit_id (keep this)
回退1个commit,已经commit的修改和还未commit的修改,都会丢失,--hard参数确保了丢失,HEAD^表示前一个commit,也可以写成HEAD~1。
HEAD^^表示前2个commit,也可以写成HEAD~2,以此类推。也可以用commit id!
$ git reset --soft ...
所有修改回退到stage状态,working area保持不变。
$ git reset --mixed ...
回退后,所有的修改都放在working area!
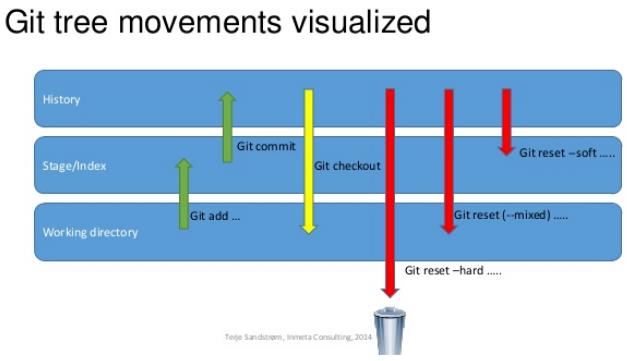
git reset是直接回退,不改变branch。git checkout是通过改变或生成新branch的方式,变相实现版本回退。
开发中常常遇到这样的场景:在某个feature分支干活,还没干完,代码还没有commit,就需要紧急处理另一个分支的问题;此时,你可以选择直接commit,这样你的log会比较难看,虽然后期可以用 git rebase -i来修复,但总是个小麻烦;另一个选择就是 git stash,暂存你的修改。
$ git stash
git stash 之后,分支所有的修改就被保存到了stash栈单独存放,git status 你会看到 clean。
如果你的修改已经staged,没关系,git stash一样可以给你保存下来,但是在恢复的时候,staged的状态会丢失,变为modified。
$ git stash push -m 'a message here'
save 后面带一个string,给你的这条stash写个comment。
$ git stash list
查看这个repo中的stash,能看到它们的index number。
$ git stash pop [index]
将stash栈中最顶上的那个恢复,这个命令会自动删除 这个stash。
$ git stash apply [index]
应用某个stash,但是不删除,这就是与pop不同之处。
$ git stash clear
删除所有stash。
$ git stash drop index
删除某一个stash。
$ git stash show [-p]
查看某个stash的信息。
git stash 的信息,不会被 git push到远端。
删除work tree中的untracked files。
$ git clean -fd
-f,--force
-d,recursively clean untracked directories
本文链接:https://cs.pynote.net/sf/202111035/
-- EOF --
-- MORE --