Last Updated: 2023-10-16 13:18:36 Monday
-- TOC --
SRAM是Static RAM的缩写。
SRAM存储器件所用的CMOS管相对较多(每bit要4--6个gate),占硅片面积大,因而功耗大,集成度低。但是因为采用一个正负反馈触发器(flip-flop)电路来存储信息,所以,只要直流供电电源一直加在电路上,就能一直保持记忆状态不变,无需定时刷新,也不会因为读操作而使状态发生改变,故无需读后再生。读写速度很快,价格较贵,一般用作高速小容量半导体存储器,比如CPU内的高速缓存Cache。
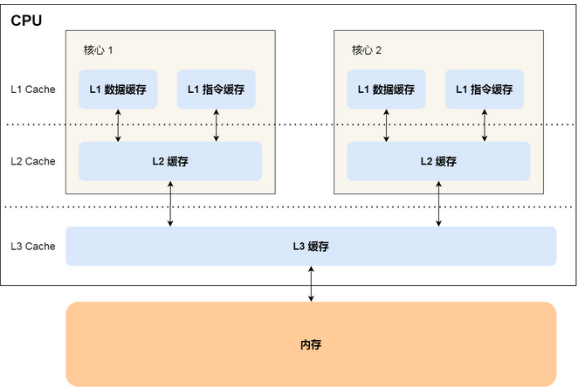
CPU Cache通常分为大小不等的三级缓存,分别是 L1 Cache、L2 Cache 和 L3 Cache。L1距离CPU最近(分为L1 Code和L1 Data),它最小,速度也最快!由于CPU Cache的实现是 SRAM,价格比内存使用的DRAM要高出不少,每生产 1 MB 大小的 CPU Cache 需要 7 美金的成本,而内存只需要 0.015 美金,成本方面相差了 466 倍,所以 CPU Cache 不像内存那样动辄以 GB 计算,它的大小是以 KB 或 MB 来计算的。
2023年,已经看到有CPU的L3 Cache超过了GB门槛...祝福人类...
CPU内部的Cache采用SRAM打造。
L3 Cache最大,而且是所有core共享!程序执行时,会先将内存中的数据加载到共享的 L3 Cache 中,再将需要的部分加载到每个核心独有的 L2 Cache,最后进入到最快的 L1 Cache,之后才会被 CPU 读取。而且,L1 cache有两个,分开缓存数据和指令!
越靠近 CPU 核心的缓存其访问速度越快,CPU 访问 L1 Cache 只需要 2~4 个时钟周期,访问 L2 Cache 大约 10~20 个时钟周期,访问 L3 Cache 大约 20~60 个时钟周期,而访问内存速度大概在 200~300 个 时钟周期之间。一次内存访问所需时间是 200~300 多个时钟周期,这意味着 CPU 和内存的访问速度已经相差 200~300 多倍了。
查看CPU Cache容量
$ cat /sys/devices/system/cpu/cpu0/cache/index0/size # L1 Instruction Cache
32K
$ cat /sys/devices/system/cpu/cpu0/cache/index1/size # L1 Data Cache
32K
$ cat /sys/devices/system/cpu/cpu0/cache/index2/size # L2 Cache
256K
$ cat /sys/devices/system/cpu/cpu0/cache/index3/size # L3 Cache
3072K
或者:
$ lscpu
查看Cache Line(最小读写单位)大小:
$ cat /sys/devices/system/cpu/cpu0/cache/index0/coherency_line_size
64
$ cat /sys/devices/system/cpu/cpu0/cache/index1/coherency_line_size
64
$ cat /sys/devices/system/cpu/cpu0/cache/index2/coherency_line_size
64
$ cat /sys/devices/system/cpu/cpu0/cache/index3/coherency_line_size
64
全都是64字节。
DRAM是Dynamic RAM的缩写。
DRAM存储元件所用的CMOS管较少(one bit one transistor),占硅片面积小,因而功耗小,集成度高。但因为采用电容存储电荷的形式来存储信息,会发生漏电现象,所以要使其保持状态不变,必须定时刷新。又因为读操作会使状态发生改变,故需要读后再生。它的读写速度相对SRAM要慢一些,价格也要低不少,比较适合用来做主存,Main Memory,即内存。
In a static RAM (SRAM), the value stored in a cell is kept on a pair of inverting gates, and as long as power is applied, the value can be kept indefinitely. In a dynamic RAM (DRAM), the value kept in a cell is stored as a charge in a capacitor. A single transistor is then used to access this stored charge, either to read the value or to overwrite the charge stored there. Because DRAMs use only a single transistor per bit of storage, they are much denser and cheaper per bit. By comparison, SRAMs require four to six transistors per bit. Because DRAMs store the charge on a capacitor, it cannot be kept indefinitely and must periodically be refreshed. That is why this memory structure is called dynamic, as opposed to the static storage in a SRAM cell.
下图是一个DDR5内存中的1bit的样子:
目前内存(主存)常用的是基于SDRAM(Synchronous DRAM)芯片技术的内存条。SDRAM的工作方式与传统的DRAM有很大不同。传统DRAM与CPU之间采用异步方式交换数据,CPU发出地址和控制信号后,经过一段延迟时间,数据才读出或写入。在这段时间里,CPU不断采样DRAM的完成信号,在没有完成之前,CPU插入等待状态而不能做其他工作。而SDRAM芯片则不同,其读写受系统时钟控制,因此与CPU之间采用同步方式交换数据。它将CPU或其他主设备发出的地址和控制信息锁存起来,经过确定的几个时钟周期后给出响应。因此,主设备在这段时间内,可以安全地进行其他操作。
个人理解:由于CPU缓存的存在,读取内存总是按块进行,每次读取的size相同,看到一个术语叫做burst buffer,因此就可以同步了,也符合了CPU缓存的运行逻辑。
DDR(Double Data Rate)SDRAM是对标准SDRAM的改进设计,通过芯片内部读写缓冲的两位预取,并利用存储器总线时钟信号的上升沿与下降沿进行两次传送来同步,以实现一个时钟内传送两次数据。类似的技术可以实现一个时钟内传送4个数据(DDR2)或8个数据(DDR3)。(在进入DDR时代前,还经历了SDR,即Single Data Rate的过度)
DIMM:Dual Inline Memory Module
双列直插式存储模块。在DIMM之前,是SIMM,Single Inline Memory Module,单列直插式内存模块。顾名思义,它们形容的是内存的结构设计。与SIMM一样,DIMM是一个硬件接口模块,在一个小电路板上包含一个或几个随机存取存储器(RAM)芯片,其引脚将其连接到计算机主板。DDRx内存,都是DIMM接口内存。DIMM是指针脚插槽,是物理结构方面的分类。DDRx是内部技术方面的分类。DIMM是内存插槽的接口模式,而DDR则指的是内存标准规范。(有各种各样名称的DIMM接口标准,用于不同场景)
通过对技术的认知,理解inline这个单词的含义,有点插队的感觉...
字节对齐后内存访问速度更快
一般对内存地址字节对齐的理解为,将要访问的内存起始地址address,对数据类型的长度进行求模运算,如果结果为0,则本次访问是内存地址对齐的,即:
address % sizeof(type) == 0
A properly-aligned fundamental data type is one whose address is evenly divisible by its size in bytes. For example, a doubleword (x86) is properly aligned when it is stored at a memory location with an address that is evenly divisible by four. Similarly, quadwords are properly aligned at addresses evenly divisible by eight. Unless specifically enabled by the operating system, an x86 processor normally does not require proper alignment of multi-byte fundamental data types in memory. A notable exception to this rule are the x86-SSE and x86-AVX instruction sets, which usually require proper alignment of double quadword and quad quadword operands.
例如,当CPU需要获取4个连续的整数(int)时,如果数据的起始地址可以被sizeof(int)整除,那么我们称本次访问是内存字节对齐的访问,反之就是没有字节对齐的访问。比如,从地址0xF1读取4字节整数,就是地址非对齐的访问。
CPU先访问自己的cache,如果数据不在cache中,再访问内存,将数据load到cache,最后还是访问cache!
内存与CPU之间的数据传输需要经过cache,当前Intel的64位CPU基本每个cacheline大小为64字节,因此一次内存访问至少可以获取64字节的数据到cache。
为什么要对齐?
简单的看来,对于一个64位的CPU,其数据总线宽度为64位,一次拥有取出8个字节数据的能力,理论上CPU应该是可以从任意的内存地址取8个连续字节的,而且不管是否对齐,硬件的设计是相同的(如果内存和CPU都是字节组织的话,那么内存应当可以返回任意地址开始连续的8字节,CPU处理起来也没有任何差异)。
然而,有些CPU并不支持非对齐的内存访问,甚至在访问的时候会发生异常(例如ARM架构的某些CPU)。而某些复杂指令集的CPU(比如x86架构),虽然可以完成非对齐的内存访问,然而CPU并不是一次性读出所需字节,而是采取多次读取对齐的内存,然后进行数据拼接,从而实现非对齐地址数据的访问。如下图(以读取4字节为例):
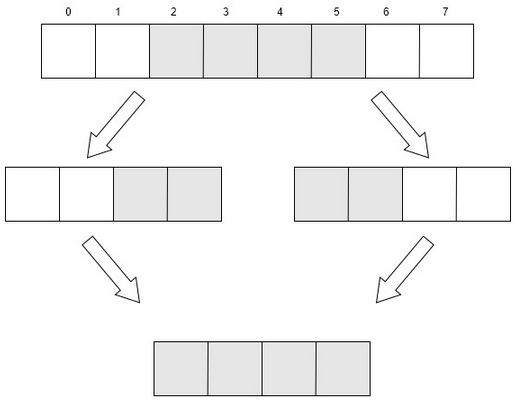
以读取4字节为例,如果数据存于内存的2-5中,在读取时实际上是先读取0-3,再读取4-7字节,再分别将2-3字节和4-5字节合并,最后得到所需的4字节数据。
那么,为什么CPU不直接读取2-5呢?因为硬件设计不支持这样做。
实际上,访问非对齐地址的内存并没有我们想象的那么简单,内存实际上由多个内存芯片组成(内存条上那些黑色的内存颗粒)。为了提高访存带宽,通常的做法是将数据分开存储,放到不同的芯片上,比如,第0-7bit(第0字节)在芯片0上储存,8-15bit(第1字节)在芯片1上存储,16-23bit(第2字节)在芯片2存储,24-31bit(第3字节)在芯片3上存储,以此类推,如下图:
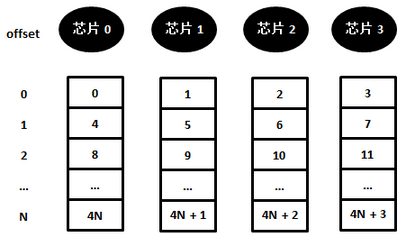
如果要获取对齐的内存地址0x00处开始的4个字节,此时,这4个字节分别存储在4个芯片中,而且都有同样的offset(=0),因此一次就可以获取到需要的数据。但如果读取非对齐的内存地址0x01处开始的4个字节,此时前3个字节存储在offset为0的三个芯片中,第4个字节存储在offset为1的芯片中。在对内存进行访问时,CPU每次只能给出一个offset,也就是说一次访问内存无法取出保存在两个不同offset中的数据,因此需要两次访问内存。
CPU以cacheline的size为读取内存的最小单位。如果地址是对齐的,这组数据会更快到达cache,然后被指令使用。现在cacheline的size一般都是64字节。
将连续的bits分开存储在不同的按array排列的存储芯片中,由硬件设计的Two-Level Decode造成。SRAM和DRAM都使用这种设计,否则实现超级庞大的decoder不现实。下图是来自《C.O.D.》的示例:
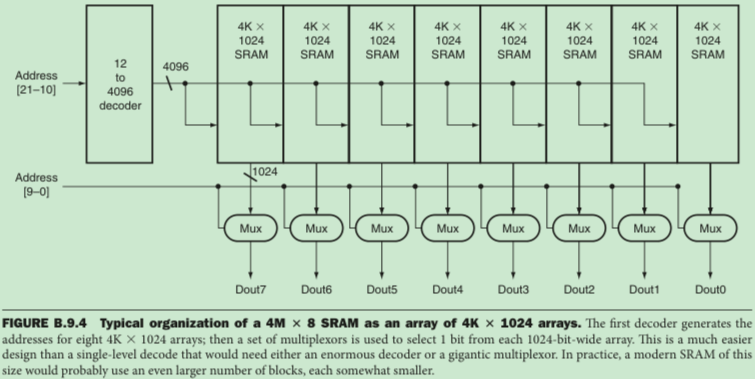
以上只是对原理的粗略介绍,作大概了解,并不是准确的细节!
编译器生成的stack中的变量地址,都会按其type和size(比如array)进行地址对齐。运行时通过malloc得到的任意size的内存起始地址,都是16字节对齐(x64)。Linux函数调用规范要求:THE STACK POINTER %RSP MUST BE ALIGNED TO A 16-BYTE BOUNDARY BEFORE MAKING A CALL。
本文链接:https://cs.pynote.net/hd/202112043/
-- EOF --
-- MORE --