Last Updated: 2024-04-14 13:38:30 Sunday
-- TOC --
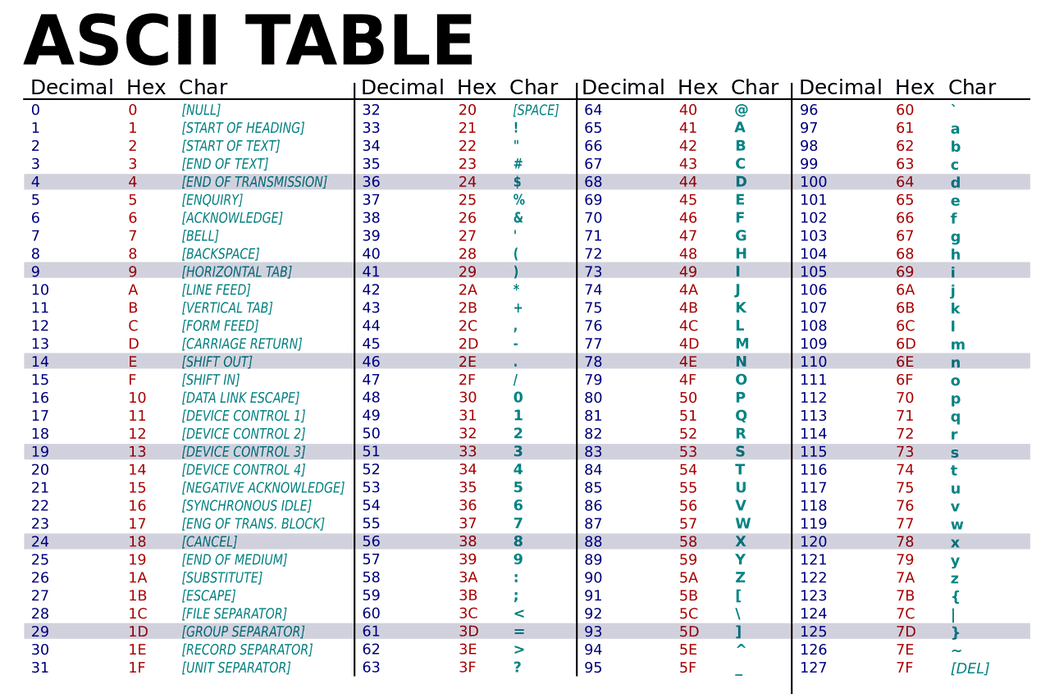
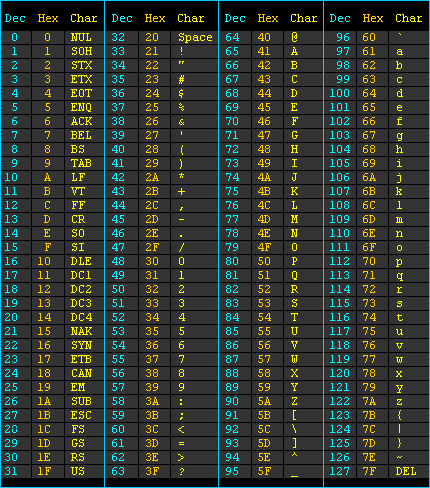
ASCII(American Standard Code for Information Interchange,美国信息互换标准代码)是一套基于拉丁字母的字符编码,共收录了128个字符,用一个字节就可以存储(实际上7bit就可以),它等同于国际标准ISO/IEC 646。
ASCII的发音[ˈæski]
ASCII 规范于 1967 年第一次发布,最后一次更新是在 1986 年,它包含了 33 个控制字符(具有某些特殊功能但是无法显示的字符)和 95 个可显示字符。
ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言。
ASCII是现今最通用的单字节编码系统,并等同于国际标准ISO/IEC 646。请注意,ASCII是American Standard Code for Information Interchange缩写,而不是ASCⅡ(罗马数字2),有很多人在这个地方产生误解。
标准ASCII只用了7个bit位,最高的1bit原是用来做奇偶校验的。
我理解的奇偶校验,通信双方先约定好采用奇校验或偶校验,然后在传输时,设置最高的1bit,用来凑出奇或偶,接收方按约定好的奇或偶的方式,检查接收是否出错。(如果同时错2bit,奇偶校验就失效了,但奇偶校验只多用1bit)
所有的编码系统,都会兼容ASCII编码,计算机内的很多软件算法,都是基于ASCII编码的特点编写的,比如大小写字母之间固定的间隔等。
这个知识点程序员一定需要了解,ASCII中,有六种不同的空格字符。
数字 --> 大写字母 --> 小写字母,这个顺序就是字符串大小的比较顺序。
著名的“回车/换行”字符,洋文分别称之为carriage return和line feed。在编程领域,这两个字符简写为 \r & \n。
为什么会有这么两个符号呢?
因为在电传打字机时代,当打印完一行之后,需要用一个控制命令把打印头复位(移到打印纸的左边),然后再用另一个控制命令把打印头往下移动一行。很自然地,这俩动作就对应了两个控制字符(CR和LF),也就是所谓的回车与换行。
ASCII字符表的开头部分,前面的32个字符,都是控制字符,很多都源自遥远的电报时代。
0o是前缀,由Python的oct函数输出。
| Decimal | Octal | Hex | Bin |
|---|---|---|---|
| 0 | 0o0 | 0x0 | 0b0 |
| 1 | 0o1 | 0x1 | 0b1 |
| 2 | 0o2 | 0x2 | 0b10 |
| 3 | 0o3 | 0x3 | 0b11 |
| 4 | 0o4 | 0x4 | 0b100 |
| 5 | 0o5 | 0x5 | 0b101 |
| 6 | 0o6 | 0x6 | 0b110 |
| 7 | 0o7 | 0x7 | 0b111 |
| 8 | 0o10 | 0x8 | 0b1000 |
| 9 | 0o11 | 0x9 | 0b1001 |
| 10 | 0o12 | 0xa | 0b1010 |
| 11 | 0o13 | 0xb | 0b1011 |
| 12 | 0o14 | 0xc | 0b1100 |
| 13 | 0o15 | 0xd | 0b1101 |
| 14 | 0o16 | 0xe | 0b1110 |
| 15 | 0o17 | 0xf | 0b1111 |
| 16 | 0o20 | 0x10 | 0b10000 |
| 17 | 0o21 | 0x11 | 0b10001 |
| 18 | 0o22 | 0x12 | 0b10010 |
| 19 | 0o23 | 0x13 | 0b10011 |
| 20 | 0o24 | 0x14 | 0b10100 |
| 21 | 0o25 | 0x15 | 0b10101 |
| 22 | 0o26 | 0x16 | 0b10110 |
| 23 | 0o27 | 0x17 | 0b10111 |
| 24 | 0o30 | 0x18 | 0b11000 |
| 25 | 0o31 | 0x19 | 0b11001 |
| 26 | 0o32 | 0x1a | 0b11010 |
| 27 | 0o33 | 0x1b | 0b11011 |
| 28 | 0o34 | 0x1c | 0b11100 |
| 29 | 0o35 | 0x1d | 0b11101 |
| 30 | 0o36 | 0x1e | 0b11110 |
| 31 | 0o37 | 0x1f | 0b11111 |
| 32 | 0o40 | 0x20 | 0b100000 |
| 33 | 0o41 | 0x21 | 0b100001 |
| 34 | 0o42 | 0x22 | 0b100010 |
| 35 | 0o43 | 0x23 | 0b100011 |
| 36 | 0o44 | 0x24 | 0b100100 |
| 37 | 0o45 | 0x25 | 0b100101 |
| 38 | 0o46 | 0x26 | 0b100110 |
| 39 | 0o47 | 0x27 | 0b100111 |
| 40 | 0o50 | 0x28 | 0b101000 |
| 41 | 0o51 | 0x29 | 0b101001 |
| 42 | 0o52 | 0x2a | 0b101010 |
| 43 | 0o53 | 0x2b | 0b101011 |
| 44 | 0o54 | 0x2c | 0b101100 |
| 45 | 0o55 | 0x2d | 0b101101 |
| 46 | 0o56 | 0x2e | 0b101110 |
| 47 | 0o57 | 0x2f | 0b101111 |
| 48 | 0o60 | 0x30 | 0b110000 |
| 49 | 0o61 | 0x31 | 0b110001 |
| 50 | 0o62 | 0x32 | 0b110010 |
| 51 | 0o63 | 0x33 | 0b110011 |
| 52 | 0o64 | 0x34 | 0b110100 |
| 53 | 0o65 | 0x35 | 0b110101 |
| 54 | 0o66 | 0x36 | 0b110110 |
| 55 | 0o67 | 0x37 | 0b110111 |
| 56 | 0o70 | 0x38 | 0b111000 |
| 57 | 0o71 | 0x39 | 0b111001 |
| 58 | 0o72 | 0x3a | 0b111010 |
| 59 | 0o73 | 0x3b | 0b111011 |
| 60 | 0o74 | 0x3c | 0b111100 |
| 61 | 0o75 | 0x3d | 0b111101 |
| 62 | 0o76 | 0x3e | 0b111110 |
| 63 | 0o77 | 0x3f | 0b111111 |
| 64 | 0o100 | 0x40 | 0b1000000 |
| 65 | 0o101 | 0x41 | 0b1000001 |
| 66 | 0o102 | 0x42 | 0b1000010 |
| 67 | 0o103 | 0x43 | 0b1000011 |
| 68 | 0o104 | 0x44 | 0b1000100 |
| 69 | 0o105 | 0x45 | 0b1000101 |
| 70 | 0o106 | 0x46 | 0b1000110 |
| 71 | 0o107 | 0x47 | 0b1000111 |
| 72 | 0o110 | 0x48 | 0b1001000 |
| 73 | 0o111 | 0x49 | 0b1001001 |
| 74 | 0o112 | 0x4a | 0b1001010 |
| 75 | 0o113 | 0x4b | 0b1001011 |
| 76 | 0o114 | 0x4c | 0b1001100 |
| 77 | 0o115 | 0x4d | 0b1001101 |
| 78 | 0o116 | 0x4e | 0b1001110 |
| 79 | 0o117 | 0x4f | 0b1001111 |
| 80 | 0o120 | 0x50 | 0b1010000 |
| 81 | 0o121 | 0x51 | 0b1010001 |
| 82 | 0o122 | 0x52 | 0b1010010 |
| 83 | 0o123 | 0x53 | 0b1010011 |
| 84 | 0o124 | 0x54 | 0b1010100 |
| 85 | 0o125 | 0x55 | 0b1010101 |
| 86 | 0o126 | 0x56 | 0b1010110 |
| 87 | 0o127 | 0x57 | 0b1010111 |
| 88 | 0o130 | 0x58 | 0b1011000 |
| 89 | 0o131 | 0x59 | 0b1011001 |
| 90 | 0o132 | 0x5a | 0b1011010 |
| 91 | 0o133 | 0x5b | 0b1011011 |
| 92 | 0o134 | 0x5c | 0b1011100 |
| 93 | 0o135 | 0x5d | 0b1011101 |
| 94 | 0o136 | 0x5e | 0b1011110 |
| 95 | 0o137 | 0x5f | 0b1011111 |
| 96 | 0o140 | 0x60 | 0b1100000 |
| 97 | 0o141 | 0x61 | 0b1100001 |
| 98 | 0o142 | 0x62 | 0b1100010 |
| 99 | 0o143 | 0x63 | 0b1100011 |
| 100 | 0o144 | 0x64 | 0b1100100 |
| 101 | 0o145 | 0x65 | 0b1100101 |
| 102 | 0o146 | 0x66 | 0b1100110 |
| 103 | 0o147 | 0x67 | 0b1100111 |
| 104 | 0o150 | 0x68 | 0b1101000 |
| 105 | 0o151 | 0x69 | 0b1101001 |
| 106 | 0o152 | 0x6a | 0b1101010 |
| 107 | 0o153 | 0x6b | 0b1101011 |
| 108 | 0o154 | 0x6c | 0b1101100 |
| 109 | 0o155 | 0x6d | 0b1101101 |
| 110 | 0o156 | 0x6e | 0b1101110 |
| 111 | 0o157 | 0x6f | 0b1101111 |
| 112 | 0o160 | 0x70 | 0b1110000 |
| 113 | 0o161 | 0x71 | 0b1110001 |
| 114 | 0o162 | 0x72 | 0b1110010 |
| 115 | 0o163 | 0x73 | 0b1110011 |
| 116 | 0o164 | 0x74 | 0b1110100 |
| 117 | 0o165 | 0x75 | 0b1110101 |
| 118 | 0o166 | 0x76 | 0b1110110 |
| 119 | 0o167 | 0x77 | 0b1110111 |
| 120 | 0o170 | 0x78 | 0b1111000 |
| 121 | 0o171 | 0x79 | 0b1111001 |
| 122 | 0o172 | 0x7a | 0b1111010 |
| 123 | 0o173 | 0x7b | 0b1111011 |
| 124 | 0o174 | 0x7c | 0b1111100 |
| 125 | 0o175 | 0x7d | 0b1111101 |
| 126 | 0o176 | 0x7e | 0b1111110 |
| 127 | 0o177 | 0x7f | 0b1111111 |
代码:
>>> for i in range(128):
... print(i, '|', oct(i), '|', hex(i), '|', bin(i))
C代码中,用\开始的序列,都是转义符号(Escape Character,也有说Escape Sequence,确实不是一个符号可以表示的)。
有些其它编程语言,比如Python,转义的语法与C基本相同。
\ddd:表示一个8进制表示的符号,最大取值\177;
\xdd:表示一个16进制的符号,最大取值\x7F;
超过取值范围的行为,跟具体编译器有关系,但基本上这是个错误!
char a = '\61'; //字符1
char b = '\141'; //字符a
char c = '\x31'; //字符1
char d = '\x61'; //字符a
char *str1 = "\x31\x32\x33\x61\x62\x63"; //字符串"123abc"
char *str2 = "\61\62\63\141\142\143"; //字符串"123abc"
char *str3 = "The string is: \61\62\63\x61\x62\x63" //混用八进制和十六进制形式
一些常用的转义符号的简写:
| 转义字符 | 意义 | ASCII码值(十进制) |
|---|---|---|
| \a | 响铃(BEL) | 007 |
| \b | 退格(BS) ,将当前位置移到前一列 | 008 |
| \f | 换页(FF),将当前位置移到下页开头 | 012 |
| \n | 换行(LF) ,将当前位置移到下一行开头 | 010 |
| \r | 回车(CR) ,将当前位置移到本行开头 | 013 |
| \t | 水平制表(HT) | 009 |
| \v | 垂直制表(VT) | 011 |
| \e | Escape | 027 |
| \' | 单引号 | 039 |
| \" | 双引号 | 034 |
| \\ | 反斜杠 | 092 |
C语言中,双引号内的是字符串,单引号内的是单个字符!
Raw String
Raw String其实就是没有转义的字符串,即其中的\不表示转移,就是\本身,但要用\\来表示。
ISO-8859-1 (Western Europe) is a 8-bit single-byte coded character set.
Also known as ISO Latin 1. The first 128 characters are identical to UTF-8 (and UTF-16).
这也是一个很常见的8bit编码方式,它只是扩展了ASCII没有用到的后128个编码位置。

原ASCII只有美元符号,Latin-1扩展了欧元符号,人民币符号,还有千分号等符号。Python标准库中的http.server模块,在解码的时候,就指定为Latin-1。
本文链接:https://cs.pynote.net/sf/202109100/
-- EOF --
-- MORE --