-- TOC --
我喜欢SQLite,因为它足够强大,做个demo或者一些数据量相对较小的场景,直接拿来就用;同时它也很小很简单。
Python底层的sqlite3库使用autocommit模式,但是Python3的sqlite3模块默认不是这样的!
autocommit的含义是,每一条修改数据库的SQL语句,都会自动commit,使修改立即生效!
The Python sqlite3 module by default issues a BEGIN statement implicitly before a Data Modification Language (DML) statement (i.e. INSERT/UPDATE/DELETE/REPLACE).
BEGIN的效果,与BEGIN DEFERRED一样,这是Python3的sqlite3模块的默认行为。begin是数据库transaction的开始,结束transaction,就要显示调用commit接口,这样做的效果,就是关闭了autocommit。
You can disable the sqlite3 module’s implicit transaction management by setting isolation_level to None. This will leave the underlying sqlite3 library operating in autocommit mode. You can then completely control the transaction state by explicitly issuing BEGIN, ROLLBACK, SAVEPOINT, and RELEASE statements in your code. 要在Python中完全自己控制数据库的transaction,设置connect对象的isolation_level=None。(isolation_level默认值是一个空字符串,除了None之外,还可以immediate或exclusive,表示transaction之间的隔离程度)
Note that executescript() disregards isolation_level; any transaction control must be added explicitly.
sqlite3有3种事务模式:DEFERRED, IMMEDIATE, or EXCLUSIVE.
DEFERRED means that the transaction does not actually start until the database is first accessed. Internally, the BEGIN DEFERRED statement merely sets a flag on the database connection that turns off the automatic commit that would normally occur when the last statement finishes. This causes the transaction that is automatically started to persist until an explicit COMMIT or ROLLBACK or until a rollback is provoked by an error or an ON CONFLICT ROLLBACK clause. If the first statement after BEGIN DEFERRED is a SELECT, then a read transaction is started. Subsequent write statements will upgrade the transaction to a write transaction if possible, or return SQLITE_BUSY. If the first statement after BEGIN DEFERRED is a write statement, then a write transaction is started.
DEFERRED表示直到commit才真正启动transaction,或者rollback取消。
transaction就是事务,分两种:read or write transaction。
DEFERED是默认的,写成 begin 或 begin defered,是一样的。python sqlite3模块的接口默认就是这种模式。
IMMEDIATE cause the database connection to start a new write immediately, without waiting for a write statement. The BEGIN IMMEDIATE might fail with SQLITE_BUSY if another write transaction is already active on another database connection.
两个客户端如果同时开始 begin immediate 事务,后启动的那个会失败。即不能同时有多个write transaction。如果一个deferred事务,执行到了insert等修改语句,这个事务也变成了write transaction,其它客户端再执行 begin immediate | exclusive ,都会失败。提示 database is locked。
sqlite3.OperationalError: database is locked
EXCLUSIVE is similar to IMMEDIATE in that a write transaction is started immediately. EXCLUSIVE and IMMEDIATE are the same in WAL mode, but in other journaling modes, EXCLUSIVE prevents other database connections from reading the database while the transaction is underway.
exclusive最厉害,这样的transaction一旦开始,其它客户端都不能连接,读取也不行,除非SQLite工作在WAL模式下。
我在sqlite3 3.31上测试发现,sqlite3默认不是WAL模式,用begin exclusive启动的transaction会排斥所有的其它连接的操作。
SQLite3默认的 journal_mode 是 delete,不是wal。还不懂这部分?
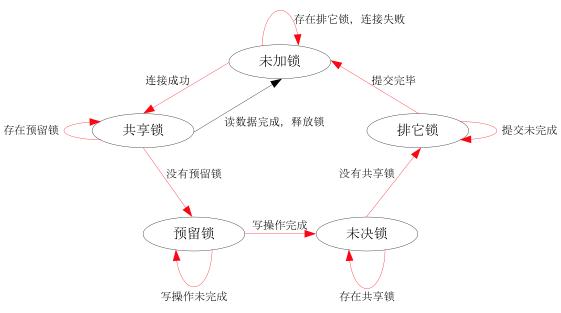
sqlite3有五种锁状态:unlocked、shared、reserved、pending、exclusive
| 锁状态 | 说明 |
|---|---|
| 未加锁-unlocked | 未对数据库进行访问(读写)之前 |
| 共享锁-shared | 对数据库进行读操作 |
| 预留锁-reserved | 对数据库进行写(缓存)操作 |
| 未决锁-pending | 等待其它共享锁关闭 |
| 排它锁-exclusive | 将缓存中的操作提交到数据库 |
commit要获取exclusive lock,因此在commit时,read transaction也会失败!不过,这个规则在WAL模式下,会有些不同。SQLite3默认的 journal_mode 是 delete,不是wal。
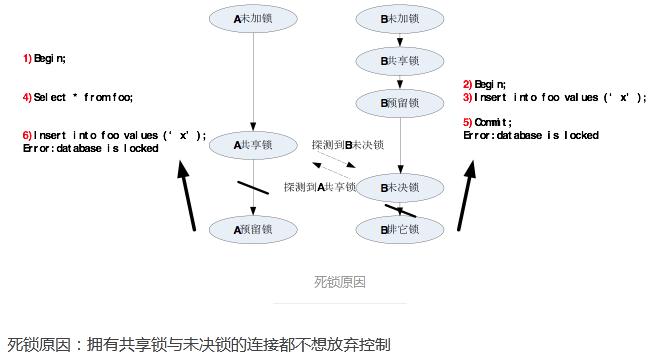
数据库并发访问是一个非常实际和重要的需求。
Python3的sqlite3模块默认有这样一条规则:同一个connect对象不能在多个线程间共享!我理解,每个connect对象,都会执行一些SQL语句,如果共享此对象,就会无法预测这些SQL语句的执行顺序,多个transaction的执行就会混杂在一起。
sqlite3.connect(database[, timeout, detect_types, isolation_level, check_same_thread, factory, cached_statements, uri])
By default, check_same_thread is True and only the creating thread may use the connection. If set False, the returned connection may be shared across multiple threads. When using multiple threads with the same connection writing operations should be serialized by the user to avoid data corruption. 如果在创建connect对象的时候,设置check_same_thread为False,此时多个线程对connect对象的操作需要用户自己管理互斥。因此,没有必要在多线程中共享connect对象。
那么,多个线程用自己的connect对象,并发操作sqlite3数据库,有问题吗?
没问题,因为sqlite3本身就自带锁机制,可以并发访问。但是,需要使用者自己处理异常情况,最典型的异常情况,就是database is locked。
Python3的sqlite3模块,默认的隐式事务的模式,其实是减少了commit的频率(也加速了代码执行),即减少了locked异常的概率。
那么,并发访问sqlite3数据库的时候,需要加锁吗?
可以加锁,但必须清楚加锁带来的问题:
不加锁呢?
不加锁的场景,就要自己处理locked异常!
Python3的sqlite3模块,在创建connect对象的时候,可以设置一个timeout,默认是5秒。它的作用是:等待timeout时间后,再抛出locked异常;如果在timeout时间内,别的线程或进程完成了commit,执行继续。
因此,个人认为,如果场景write transaction很多很频繁,就考虑自己加锁;如果write transaction不多也不频繁,主要是read transaction,简单处理,就不要加锁了,处理一下locked异常即可,而Python3的sqlit3模块提供的timeout机制非常好用。
一个减少冲突的思路:如果表之间可以相互独立存在(比如没有外键约束时),可以考虑将它们放在不同的数据库中(不同的文件),并发访问不同的数据库是没有冲突的。
:memory:如果在创建connect的时候,数据库名为:memory:,这表示此数据库在内存中。在内存中快呀!!
但是,我的测试结果是,这个在内存中的数据库,不能跨进程访问。即A进程创建的内存数据库,在别的进程中不可见。不仅如此,同一进程内的线程之间也不可见。
似乎这个内存数据库,只与创建它的connect对象有关系,那么如果要多线程多进程间共享此数据的访问,就只能共享这个connect对象了!(check_same_thread设置为False)
这部分的细节,也许是我测试不够充分....?
有人说外键约束会降低数据库的速度,据传很多互联网应用都不使用外键,而是通过程序本身的逻辑来保证约束条件。anyway......
SQLite从3.6.19开始支持外键约束,但是默认是关闭的,要通过pragma foreign_keys=on来打开此功能。
下面是我之前写的关于此问题的测试代码:
import sqlite3
db = sqlite3.connect(':memory:', isolation_level='exclusive')
db.execute('pragma foreign_keys=on')
db.execute('create table if not exists a1'
'(id integer primary key, content text)')
db.execute('create table if not exists b1'
'(id integer references a1(id), content text)')
data = [
(1,1),
(2,2),
(3,3),
(4,4),
(5,5)
]
db.executemany('insert into a1 values (?,?)', data)
try:
db.execute('insert into b1 values (6,6)')
except Exception as e:
print(repr(e)) # raise
db.execute('insert into b1 values (1,1)')
try:
db.execute('delete from a1 where id=1')
except Exception as e:
print(repr(e)) # raise
db.commit()
db.close()
运行这段代码,有两次raise:
IntegrityError('FOREIGN KEY constraint failed')
IntegrityError('FOREIGN KEY constraint failed')
b1表的id列依赖a1表的id列。向b1表插入(6,6)时,a1表没有id=6的项,raise;删除a1表id=1的项,由于b1表已经存在id=1的项,删除后会破坏约束关系,raise。
reference时,只指定table,没有column,默认reference table的primary key。
sqlite3外键约束引用的列,必须要有unique约束
测试代码:
sqlite> pragma foreign_keys=on;
sqlite>
sqlite> create table aa(id integer primary key, content text);
sqlite> insert into aa values (1,1);
sqlite> insert into aa values (2,1);
sqlite> insert into aa values (3,1);
sqlite> .mode column
sqlite> select * from aa;
id content
-- -------
1 1
2 1
3 1
sqlite> create table bb(content text references aa(content));
sqlite> insert into bb values (1);
Error: foreign key mismatch - "bb" referencing "aa"
sqlite> insert into bb values (2);
Error: foreign key mismatch - "bb" referencing "aa"
sqlite> insert into bb values (3);
Error: foreign key mismatch - "bb" referencing "aa"
sqlite> insert into bb values ('1');
Error: foreign key mismatch - "bb" referencing "aa"
sqlite> insert into bb values ("1");
Error: foreign key mismatch - "bb" referencing "aa"
aa表的content列,由于没有unique约束,导致bb表无法insert数据。在创建bb表的时候,aa表里已经有相同的content row,但是create table不会检查,这一步没有错误。直到insert into bb的时候,sqlite3提示 foreign key mismatch。解决这个问题,就要在创建aa表的时候,给content列加上unique约束。
另一种subtle的情况,aa表的content列没有unique约束,但是实际情况是unique的(由程序逻辑保证),这时也一样会报错:
sqlite> create table c1(id integer primary key, content text);
sqlite> insert into c1 values (1,1);
sqlite> insert into c1 values (2,2);
sqlite> select * from c1;
id content
-- -------
1 1
2 2
sqlite> create table c2(content text references c1(content));
sqlite> insert into c2 values (1);
Error: foreign key mismatch - "c2" referencing "c1"
sqlite> insert into c2 values (2);
Error: foreign key mismatch - "c2" referencing "c1"
sqlite>
sqlite> insert into c2 values (3);
Error: foreign key mismatch - "c2" referencing "c1"
表c1的content列没有unique约束,但是实际情况是unique的,一样报错。可以理解为:aa表的content列虽然现在的数据满足unique,但是不保证以后的insert into操作,不会导致重复数据!
外键约束之ON UPDATE/DELETE
ON UPDATE和ON DELETE后面可以定义动作有:NO ACTION, RESTRICT, SET NULL, SET DEFAULT 或者 CASCADE。
下面是一个 on delete cascade的测试:
sqlite> create table aa(id integer primary key);
sqlite> insert into aa values(null);
sqlite> insert into aa values(null);
sqlite> insert into aa values(null);
sqlite> insert into aa values(null);
sqlite> insert into aa values(null);
sqlite> select * from aa;
1
2
3
4
5
sqlite> create table bb(id int references aa on delete cascade, content text);
sqlite> insert into bb values (2,'aaaaaaa');
sqlite> insert into bb values (2,'aaaaaaa');
sqlite> insert into bb values (2,'aaaaaaa');
sqlite> select * from bb;
2|aaaaaaa
2|aaaaaaa
2|aaaaaaa
sqlite> pragma foreign_keys=on;
sqlite> delete from aa where id=2;
sqlite> select * from aa;
1
3
4
5
sqlite> select * from bb;
sqlite>
SQLite中每个表都默认包含一个隐藏列rowid,使用WITHOUT ROWID定义的表除外。通常情况下,rowid可以唯一的标记表中的每个记录。表中插入的第一个条记录的rowid为1,后续插入的记录的rowid依次递增1。即使插入失败,rowid也会被加一。所以,整个表中的rowid并不一定连续,即使用户没有删除过记录。
由于唯一性,所以rowid在很多场合中当作主键使用。在使用的时候,select * from tablename并不能获取rowid,必须显式的指定。例如,select rowid, * from tablename 才可以获取rowid列。查询rowid的效率非常高,所以直接使用rowid作为查询条件是一个优化查询的好方法。
sqlite> .schema
CREATE TABLE stocks (name text, quantity integer);
sqlite> insert into stocks values ("a",123);
sqlite> select * from stocks;
a|123
b|234
c|345
d|456
e|567
a|123
sqlite> select rowid,* from stocks;
1|a|123
2|b|234
3|c|345
4|d|456
5|e|567
6|a|123
rowid是自动就有的,但也可以在定义table的时候,手动指定,此时一定要使用INTEGER PRIMARY KEY(大小写都OK)。写成INT是不可以的。
自定义integer primary key column的好处:
NOT NULL UNIQUE 约束。INTEGER PRIMARY KEY 不自带 AUTOINCREMENT 约束,这一列会增加,也有可能重复利用被删除的数字,如果带上 AUTOINCREMENT 约束,就不会重复利用被删除的数字,一直增加,直到触及最大值9223372036854775807。
来看一下NOT NULL UNIQUE的效果:
sqlite> create table aa(id integer primary key);
sqlite> insert into aa values (null);
sqlite> insert into aa values (null);
sqlite> insert into aa values (null);
sqlite> insert into aa values (null);
sqlite> insert into aa values (null);
sqlite> select * from aa;
1
2
3
4
5
对于SQLite而言,INT 和 INTEGER 是不一样的。如果在 CREATE TABLE 的时候,类型写成了 INT,就没有这个效果! INT PRIMARY KEY 被称为 ROWID Alias列。
本文链接:https://cs.pynote.net/sf/sqlite/202203182/
-- EOF --
-- MORE --